

In vorangegangenen Artikeln haben wir das Thema Fake News im Zusammenhang mit der Wahl von Trump behandelt. Die gesellschaftliche Relevanz des Themas hat beim Bayerischen Rundfunk für den Aufbau eines “BR-Verifikationsteams” geführt und sogar Google und Facebook zu Reaktionen genötigt, die sich bisher immer weigern, ihre Rolle als Verleger anzuerkennen. Es ist wichtig, dass wir alle das Thema ernst nehmen, denn Manipulation und der fahrlässige Umgang mit persönlichen Daten darf nicht toleriert werden. Um richtig zu handeln, muss man die Mechanismen verstehen. Dabei spielt die digitale Kundenanalyse eine große Rolle (und weniger die Firma Cambridge Analytica mit ihrem mehr als fragwürdigen Geschäftsgebaren). Deshalb wird hier das Ocean-Modell und seine Anwendung in der Praxis näher betrachtet.
Das Ocean-Modell oder die Big Five ist ein seit den 30er Jahren weiter entwickeltes Modell zur Beschreibung der menschlichen Persönlichkeit. Dabei wird die Persönlichkeit mit Hilfe von fünf verschiedenen Parametern analysiert: Offenheit für Erfahrungen, Gewissenhaftigkeit, Geselligkeit, Rücksichtnahme, Kooperationsbereitschaft, Empathie sowie Verletzlichkeit. Ähnliche Modelle der Clusterung kennt man von den Sinus-Mileus oder den Sigma-Mileus, die die Parameter “soziale Lage” (sprich Einkommen) und “Grundorientierung” (sprich beharrend oder verändernd) für eine Einteilung gewählt haben, oder dem Semiometrie-Modell von TNS. An dieser Stelle braucht man nicht diskutieren, dass derartige Modelle wie alle Modelle nur Annäherungen darstellen und die menschliche Persönlichkeit nur begrenzt erfassen. Hierzu genügt ein Blick auf den englischsprachigen Wikipediaeintrag und den Links zur Kritik am Modell.
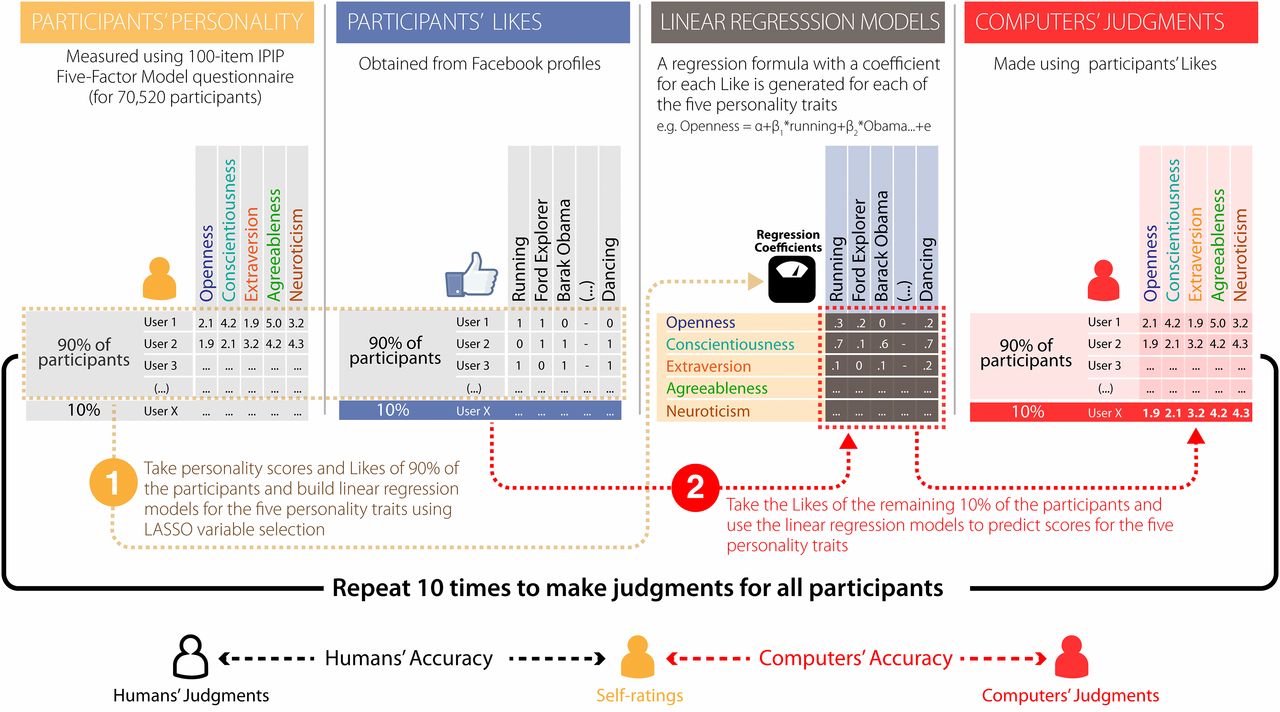
Nach Kosinski werden die Zielgruppen durch einen Fragebogen auf Facebook sowie deren Verhalten (durch likes sichtbar) analysiert und danach anhand von Wahrscheinlichkeitsberechnungen auf Eigenschaften festgelegt. Damit steht schon viel mehr Material zur Verfügung wie bei klassischen Abfragen, aber natürlich wie immer noch zu wenig, um die gesamte Persönlichkeit zu erfassen. Ob diese Hochrechnungen z.T. valider sind als die von Bekannten und Freunden hängt a) von den Fähigkeiten der Freunde ab (und deren Selbstreflektion, die der eines Psychotherapeuten nahe kommen muss, sollen sie möglichst unvoreingenommen den anderen beurteilen) und b) vom Umfang der Angaben und der Bedeutung derselben für den Probanden. (Unsere Testergebnisse waren so, dass unsere Freunde und Angehörige in ihrer Analyse unserer Persönlichkeit doch deutlich besser waren, trotz der vollmundigen Werbeaussagen.) Die Arbeiten von Michael Kosinski sind öffentlich zugänglich unter http://www.pnas.org/content/110/15/5802.full oder http://www.pnas.org/content/112/4/1036.full.
Was dieses Modell (und ähnliche wie das HEXACO-Modell) aber zur Zeit so interessant macht, ist seine lexikalische Basis. Denn über die Jahrzehnte wurden über 18.000 Begriffe gesammelt und den jeweiligen Parametern zugeordnet. Das spielte bisher nur bei den klassischen Fragebögen eine Rolle, wenn man prüfen wollte, ob ein Proband z.B. gewissenhaft ist und man ihm entsprechende Begriffe zur Auswahl vorlegte. Mit dem mobilen Web bietet sich aber seit ein paar Jahren plötzlich ein nie versiegender Quell an Texten von und über die Zielgruppen. Es ist das Paradies für jeden Modellbauer, weil er jetzt seine Zielgruppen mit Big oder Smart-Data-Analysen wunderbar in seinem Setzkasten verorten kann. Und zwar viel genauer als mit jeder Fokusgruppe oder den paar Telefoninterviews, die sein Budget ihm erlaubten. Denn die Zielgruppen sagen ja selbst und ohne Druck ganz viel über sich aus.
Um diese Daten sinnvoll miteinander verknüpfen zu können, braucht es so etwas wie eine lexikalische Zuordnung. Semantische Analysen sind deshalb nicht trivial, weil sie prinzipiell mit einem Problemen zu kämpfen haben: Jeder spricht wie ihm der Schnabel gewachsen ist und was er genau damit meint, das weiß der Redner/Schreiber oft selbst nicht so genau. Um es mit der aus der Semiotik bekannten Terminologie auf den Punkt zu bringen: Signifikat, Signifikant und Referent sind nie dasselbe. Der reale “Golf” (Referent) ist nicht das Wort “Golf” (Signifikant) und schon gar nicht die Bedeutung (Signifikat) im Sinne von Werten und Assoziationen, die der Redner damit verknüpft (wie z.B. Auto, Meeresbucht, Sportart mit ihren jeweiligen positiven oder negativen Assoziationen hierzu).
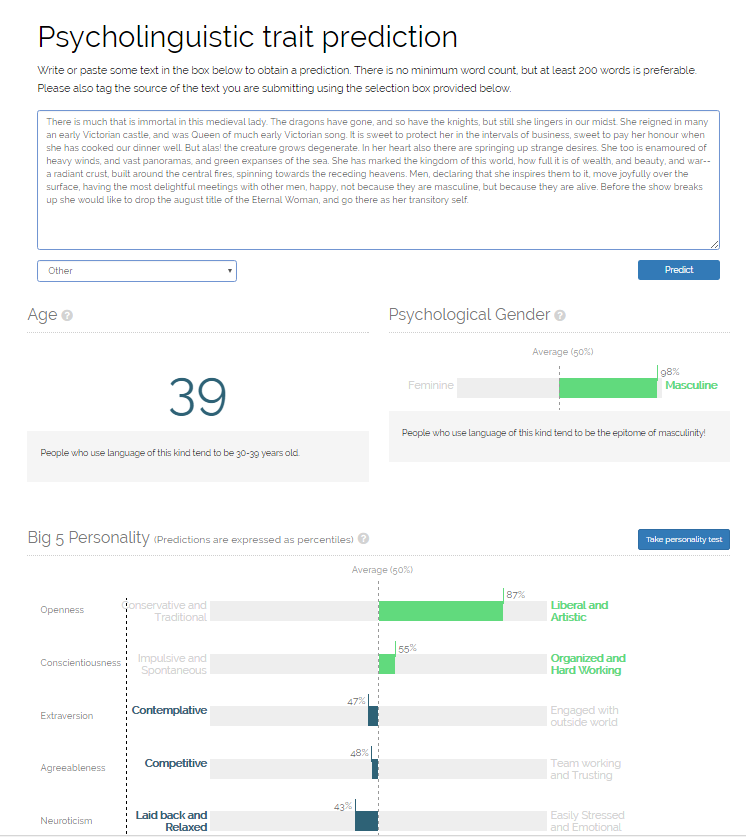
Auf der Testseite der University of Cambridge kann man einen Text eingeben und nach dem OCEAN-Modell analysieren lassen. Durch die Freigabe des eigenen Facebook-Profils lassen sich auch verschiedene Persönlichkeitstests durchführen. Die Hochrechnungen haben alle noch mit den klassischen Problemen der künstlichen Intelligenz zu kämpfen. (Quelle/Copyright: applymagicsauce.com)
Sprache ist immer nur im Kontext zu verstehen und deshalb mühen sich z.B. IBM, Facebook oder Google auch so ab mit der Künstlichen Intelligenz.
Aber:
- Mit Modellen wie OCEAN erhalten sie ein Werkzeug, das viel genauer ist als die bisherigen. Denn sie können den vorliegenden Thesaurus nutzen wie ein Schlagwortregister, das ihnen schnell eine Zuordnung erlaubt, die sicher nicht zu 100% genau ist, aber nach dem Pareto-Prinzip für 80% taugt. Den Rest können die jeweiligen Datenbanken schrittweise verbessern, denn mit jedem Eintrag lernen die Programme hinzu und können ihre Ergebnisse optimieren.
- Big Data heißt heute, dass ich Zusammenhänge erkennen kann, die mir vorher nicht bewußt wurden. Am Beispiel der Analyse von Rezepten wird das deutlich. Durch die reine Häufigkeit von Begriffen in einem gewissen Kontext wird klar, in welche Kategorien diese Begriffe gehören. Das Softwareprogramm weiß nichts von Gemüse und Fleisch, aber aus der Analyse des Gebrauchs des Begriffes Huhn weiß es, dass es häufiger im Cluster Fleisch vorkommt. So funktioniert digitale Kundenanalyse: Da der Mensch nun mal ein Herdentier ist, sagt die Häufigkeit der Zuordnungen auch etwas über die Wahrscheinlichkeit aus. Das ist nicht die Wahrheit, aber es lässt sich ganz gut damit arbeiten, wenn man es nicht mit den Menschen zu tun hat, die sich bewußt nicht im Mainstream aufhalten. Und diese sind meist Künstler, Intellektuelle oder andere Sturköpfe, auf die man in der Politik oder Wirtschaft gerne verzichtet.
Der digitale Raum bietet den Kontext für die automatisierte Analyse von Begriffen wie “Ausländer”, “Gutmenschen” oder “Sylvesternacht”. Indem die Algorithmen die Bezüge herstellen zu Ort, Zeit und allen anderen Äußerungen wie auch Aktionen (likes, shares, Antworten…) wird sehr schnell deutlich, welche Gesinnung hinter den jeweiligen Begriffen steckt. Sie sind nicht mehr neutral. Wir mögen uns dagegen sträuben, dass wir so einfach gestrickt sind, aber zu 80% sind wir das.
Und das ist vor allem für die interessant, die genau wissen, was sie wollen, z.B. die Populisten bei Wahlen oder Marketingverantwortliche mit einer klaren Markenstrategie und Produktbotschaft. Sie können nämlich mit einer größeren Wahrscheinlichkeit als bisher erkennen, wer mit welchen Interessen auf was reagiert.
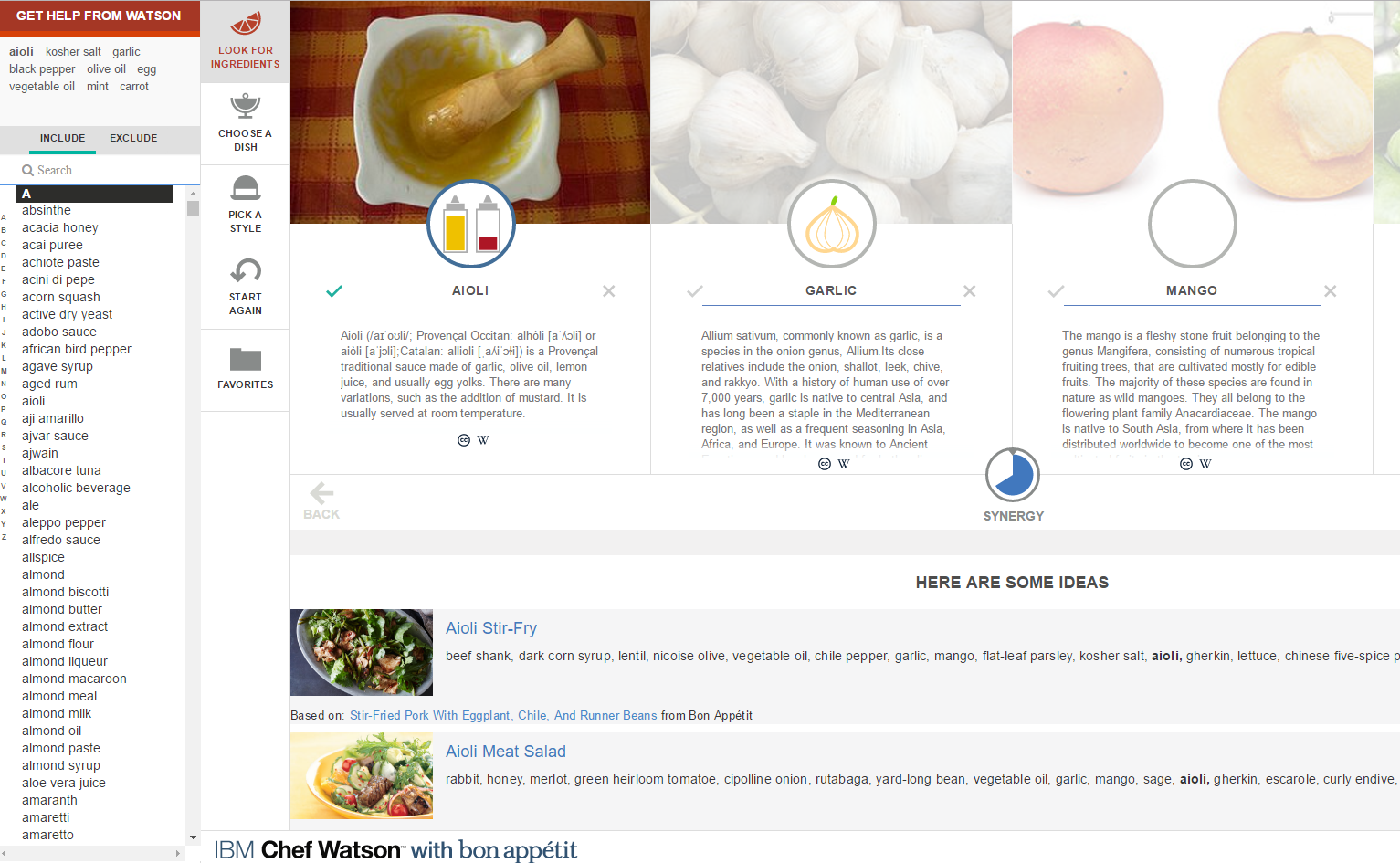
IBM und Watson laden zum Kochen mit KI ein. Man wähle einfach einen Begriff in der Menüleiste und erhalte dann passende andere Zutaten und Gerichte. Durch Big Data werden Kombinationen sichtbar, die vorher verborgen blieben. Big Data macht einen nicht schlauer über Aioli, aber Kombinationen, Verortungen, Bezüge werden sichtbar und ihre Häufigkeit. Darum geht es auch bei den semantischen Analysen in den oben genannten Modellen: Wer sich positiv zu Spaghetti Bolognese geäußert hat, könnte auch an Parmesan Interesse haben, denkt aber vielleicht nicht sofort an Erdbeeren. Wer für den Klimawandel ist, könnte bei Greenpeace sein. Aber wo erreiche ich ihn vielleicht noch? Hier beginnt Smart Data.
Im Marketing gilt, dass der Erfolg wächst, wenn man genau weiß, was man selbst will und was die Zielgruppe will. Wie bei Tinder ist der Match dann schneller. Dasselbe gilt für Populisten, die im Vergleich zu besonnenen Politikern den Vorteil haben, dass sie an Wahrheit und Verantwortung weniger Interesse haben und deshalb holzschnittartige Aussagen auch als Wahrheit verkaufen. Sie wissen genau, wogegen sie sind und können damit klar Zielgruppen identifizieren und direkt ansprechen.
Fazit
- Wer heute seine Zielgruppen erfassen will, muss den digitalen Kontext im Blick haben. Das heißt nicht, dass die bisherigen Aktivitäten fallen gelassen werden. Der persönliche Kontakt, die direkte Ansprache, der Austausch etc. sind nach wie vor wichtig und hier müssen Unternehmen präsent sein. Und es gibt genügend Räume, die nicht erfasst werden durch die sozialen Netzwerke. Zum Glück. Aber der Vorteil ist enorm, wenn man sein Raster für die Kundenanalyse auf der Datenbasis macht, die am größten ist. Und das ist zweifellos der digitale Raum. Mehr dazu in unserem Buch über Buyer Personas.
- Eine klare Markenbotschaft heißt nichts anderes, als zu wissen, was man will. Und um das zu entwickeln braucht man Zeit. Wir sehen das in unseren Projekten zur Kundenanalyse mit Unternehmen oder der Entwicklung von Start-ups und eigenen Plattformen. Der Aufwand für die Definition des Ziels und der eigenen Kunden muss betrieben werden, will man in der Folge die Daten für die Weiterentwicklung nutzen.
- Die Verantwortung wächst. Manipulation ist nicht tolerierbar. Und doch machen wir es selber täglich, wenn wir andere von unseren Ideen überzeugen wollen. Setzen wir hier bewusst Werkzeuge ein in der Ansprache unserer Kunden, dann sollten wir uns immer genau bewusst sein, wo wir den Standards der Werbung entsprechen und wo wir diese Grenze überschreiten. Die Speicherung von Daten über unsere Kunden und die jetzt und künftig damit möglichen Manipulationen verlangt von uns allen, dass wir wachsam und verantwortlich damit umgehen. Wir verweisen auf unseren Beitrag zur Verantwortung der Medien und Timothy Garton Ash und unsere Darlegung zu Kundendaten und den TED-Talk von Ekström zur Macht von Google. Am Beispiel der Bearbeitung des Fotos von Michelle Obama nach dem Wahlsieg hatte Google eingegriffen, nach Breiviks Attentat in Oslo nicht. Das bedeutet Macht und die Aufgabe, verantwortungsvoll damit umzugehen.
Pingback: Skandal um Facebook & Cambridge Analytica - Projecter GmbH
Pingback: So entwickelt man eine Buyer Persona in vier Schritten | smart digits
Pingback: Wozu braucht man eigentlich heute noch Buyer Personas? | smart digits
Pingback: Das Schulbuch der Zukunft | smart digits
Pingback: Fake News, Trump und die digitale Kundenanalyse – Teil 2 | smart digits
Pingback: Die Woche im Rückblick 03.02. bis 09.02.2017 – Wieken-Verlag Autorenservice