

Von den Anfängen von Google bis heute haben Suchmaschinen eine rasante Entwicklung hingelegt. Sie zeigt sich in der Online-Suche nach Web-Inhalten und prägt die Kundenerwartung in Consumer-Anwendungen und Fachdatenbanken. Ist man einmal den Komfort und die Usability der Google-Suche gewohnt, wird man sie kaum an anderer Stelle missen wollen. Mit sprachgesteuerten Assistenten und visueller Suche entwickeln sich aktuell neue Paradigmen in den Suchsystemen, die großes Potenzial für die Weiterentwicklung der nächsten Generation Content-Anwendungen haben. Was bedeuten diese Innovationen für Content-Anbieter im Netz? Ein aktueller Überblick über die Entwicklung der Online-Suche:
Von der Keyword-Suche zum Knowledge-Graph
Auf Basis der anfangs zwar hochskalierten, aber vom Prinzip her relativ einfachen Volltext-Indexierung mit darauf aufsetzender Keywordsuche hat Marktführer Google viele Entwicklungsschritte gemacht, die der Suche immer mehr Intelligenz beibringen und neue Funktionen realisieren. Denn eine reine Volltextsuche kann zwar auch große Dokument-Pools erschließen, hat aber auch wesentliche Nachteile: Sie weiß zunächst einmal nichts über die Bedeutung der gesuchten Begriffe im Kontext und kann deswegen die Bewertung der Relevanz eines Dokumentes für einen Suchbegriff nur anhand von statistischen Merkmalen vornehmen. Die so auf Basis von Kriterien wie Worthäufigkeit oder Wortdichte ermittelten Relevanz-Wahrscheinlichkeiten sind zwar oft stimmig, können aber inhaltlich auch komplett daneben liegen. Und solche Kriterien sind leicht manipulierbar. So bestand denn auch in den Frühzeiten der Google-Suche SEO oftmals im künstlichen Anfüttern von Dokumenten mit populären Keywords – letztlich oft mit dem Ziel, Relevanz vorzutäuschen, wo ein Dokument sie an sich gar nicht hatte.
Neben vielen Anpassungen und Evolutionsstufen in der Relevanzgewichtung für die Keyword-Suche war sicher einer der entscheidendsten Meilensteine für die Suche die Einführung des Knowledge Graph: Mit diesem Werkzeug bekommt die Suche als zusätzliche Datenquelle eine semantische Ontologie, mit der Begriffe, Konzepte und Objekte (z.B. Personen, Orte, Firmen) nicht nur als solche erkannt, sondern auch mit anderen Objekten in Beziehung gesetzt werden können. Typisches Beispiel dafür: Die Eingabe von “Angela Merkel” wird nicht mehr als reiner Text behandelt, sondern die Suchmaschine erkennt, dass es sich um eine Person handelt, die dazu die Rolle “Bundeskanzlerin” für das Land “Bundesrepublik Deutschland” hat.
Auf diese Weise können einzelne Dokumente aufgrund des so auf sie anwendbaren semantischen Netzwerks sehr viel besser auf ihre Relevanz für eine bestimmte Suche hin bewertet werden. Dabei ist es möglich, aufgrund der Rolle eines Objektes noch weitere Daten und Informationen aus verschiedenen Quellen automatisiert zuzuordnen und aggregiert auszugeben. Die Google-Suche realisiert dies seit geraumer Zeit mit den “Knowledge Boxes”, die zusätzlich zu den Trefferlisten ausgegeben werden. Ein Beispiel: Bei Eingabe von “Nick Hornby” erkennt die Suchmaschine diese Person als Schriftsteller und aggregiert nicht nur Ergebnisse aus der Bildsuche und seinen Wikipedia-Artikel hinzu, sondern auch die Buchausgaben seiner Veröffentlichungen sowie ggf. verwandte Medien:
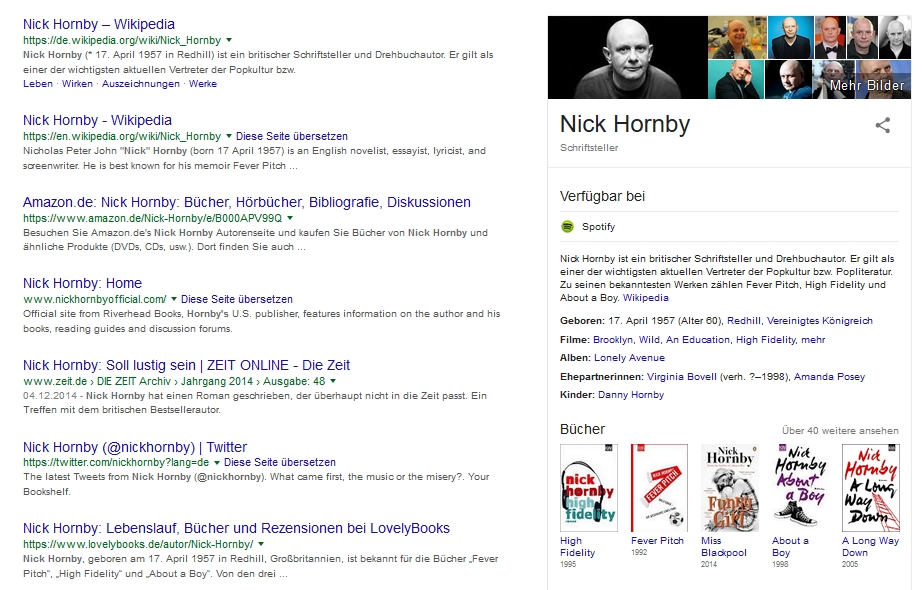
Die Knowledge-Box: eine sinnvolle Erweiterung der Trefferliste, hier am Beispiel des Schriftstellers Nick Hornby (Quelle: eigener Test, Copyright: google.com)
Wie The Digital Reader jüngst berichtete, wurde für Bücher in der US- und UK-Version der Google-Suche sogar eine direkte Kaufmöglichkeit für Buch und eBook aus der Trefferliste heraus eingeführt – eine Neuerung, die uns sicherlich in der Zukunft für immer mehr Produkttypen erwartet. Individuelle Knowledge-Box-Inhalte werden für immer mehr verschiedene Objekte realisiert, z.B. für Filme, Orte, Firmen oder auch für viele unterschiedliche Produkttypen. Datenquellen wie Bildsuche und Wikipedia werden dabei fast immer eingebunden und je nach Objekttyp kommen oft Quellen wie Youtube, Google Maps/Places oder auch diverse Online-Shops zum Einsatz. Die im Knowledge Graph ermittelten Elemente wie Begriffsdefinitionen und Kurzergebnisse/Kategorien werden mittlerweile auch in der Ausgabe des sprachgesteuerten Assistenten Google Now verwendet und weisen damit auf die nächste Evolutionsstufe hin: die sprachgesteuerte Suche mit Ausgabe der Ergebnisse ohne Trefferliste.
Use Cases für Fachdatenbanken
Das Prinzip der Objekterkennung über semantische Thesauri und Ontologien mit zusätzlicher Aggregierung weiterer Informationen neben Trefferlisten und Dokumenten hat sich als so erfolgreich erwiesen, dass immer mehr Anwendungen Funktionen auf dieser Basis realisieren – in allen Zielgruppen- und Anwendungsbereichen.
Ideal eignen sich dazu beispielsweise Anwendungen aus Fachbereichen wie Recht, Wirtschaft, Steuern, Medizin und Technik – oder überall dort, wo ein stark normierter Kanon von feststehenden Fachbegriffen mit klar verortbaren, sinnvollen Zusatzinformationen gegeben ist. Ein Beispiel wie das des Fachdatenbank-Anbieters NWB zeigt den Nutzen klar auf einen Blick: In einer Applikation für Steuerberater werden für die gängigsten Steuerarten und steuerlich relevanten Begriffe Kurzdefinitionen mit Angabe der wesentlichen Besteuerungsmerkmale hinterlegt, die als “Schnelle Antwort” in der Trefferliste noch vor den Dokumenten eingebunden wird:
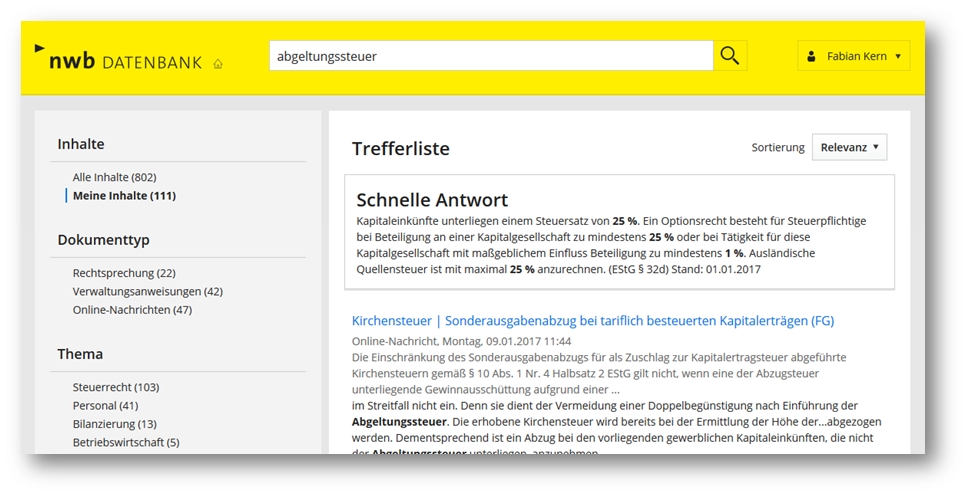
Die “Schnelle Antwort”: Letztlich eine fachlich adaptierte Variante der Knowledge-Box aus der Google-Suche (Quelle/Copyright: datenbank.nwb.de)
Ähnliche Use Cases gibt es viele, z.B. für medizinische Fachdatenbanken (Krankheiten, Symptome, Medikamente) oder Wirtschaftsdatenbanken (Firmen, Wirtschaftskennzahlen), für die Knowledge-Graph-Funktionen einen direkten Zusatz-Nutzen bringen. Und mit semantischen Systemen wie z.B. moresophy stehen erprobte Standard-Applikationen für diesen Zweck bereit, die schon in vielen Content-Szenarien von Verlagen, Medienhäusern und Online-Anbietern Einsatz finden.
In den USA wurde jüngst ein Beispiel vorgestellt, das die Anwendungsintegration noch weiter treibt: Moderne Entwicklungsumgebungen für Software besitzen standardmäßig syntaktische Prüfungs-Funktionen, die Programmfehler schon vor der Ausführung erkennen. In einem Plugin wurde nun erstmals eine Funktion realisiert, die nicht nur einen solchen Fehler erkennt, sondern auch die Entwickler-Knowledgebase Stack Overflow nach ähnlichen Problemen und dort vorgeschlagenen Lösungen hin durchsucht – dem Entwickler also eine direkte Hilfe zur Lösung seines fachlichen Problems bietet. Ähnliche Use Cases sind durchaus auch für Consumer-Anwendungen vorstellbar, z.B. durch Auswertungen der Datenbasis von gutefrage.net – oder für überhaupt alle Datenquellen, die eine Knowledgebase-Struktur haben.
Vom Knowledge Graph zur Antwort auf alle Fragen
So nützlich der Knowledge Graph ist – die Entwicklung bleibt nicht an dieser Stelle stehen: Die nächste Evolutionsstufe der Suche besteht darin, auch Struktur und Inhalt von Fragestellungen in natürlicher Sprache zu erkennen und dazu sinnvolle Antworten zu formulieren. Treiber dieser Entwicklung sind dabei sprachgesteuerte Assistenten wie Google Now. Die Fähigkeiten zur Fragen-Erkennung und Antwort-Generierung sind aber auch in der Desktop-Version der Google-Suche verbaut und können bereits jetzt an vielen Beispielen getestet werden:
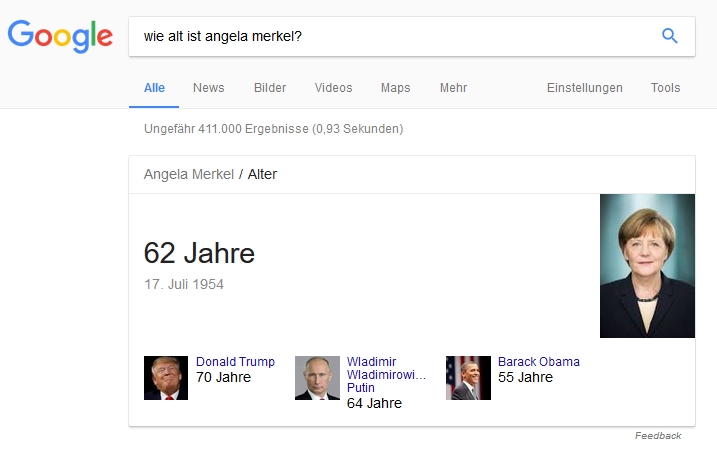
Viele Fragen, die direkt mit einer Aussage, einer Zahl oder einem Begriff beantwortbar sind, werden bereits auf diese Weise behandelt. Ebenso ist in die Suche ein kompletter Taschenrechner und die Umrechnung von Maßeinheiten und Währungen eingebaut. Aber auch komplexere Fragen werden oft schon direkt mit einer Knowledge-Box beantwortet:
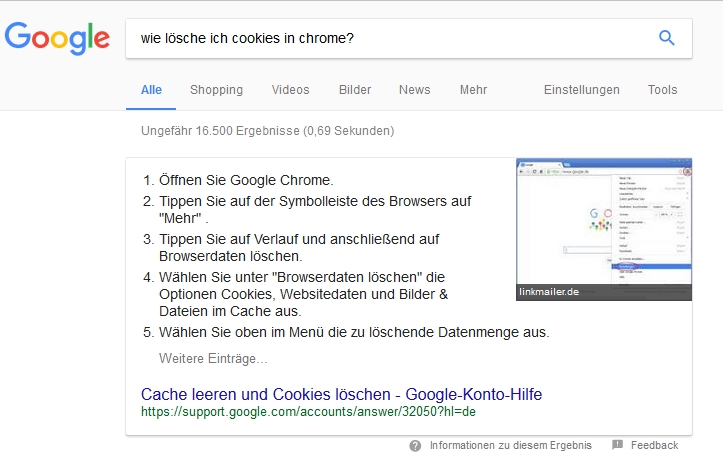
Wie an dieser Stelle zu erkennen ist, wird die Antwort zwar noch aus einer Google-eigenen Knowledgebase extrahiert, aber bereits neben den Suchergebnissen und in direkt erfassbarer Struktur dargestellt. Aber selbst wenn diese Snippet-Generierung nicht klappt, den Effekt dazu kann sich mittlerweile auch jeder PC-Anwender bei Software-Problemen zunutze machen: Ist die Frage einigermaßen sinnvoll formuliert, führt die Suche fast immer zum Ziel. Bei Fragen wie “Wie entferne ich in Excel doppelte Werte aus einer Spalte?” liegt die Wahrscheinlichkeit bei nahezu 100%, dass im ersten Suchtreffer eine sinnvolle und nützliche Antwort enthalten ist.
Noch spannender sind komplexere Abfragen unter Berücksichtigung mobiler Kontexte: Ist man beispielsweise in Hamburg unterwegs, und stellt auf seinem Smartphone die Frage “Wo gibt es hier die besten Fischbrötchen?”, läuft eine mehrstufige Abfrage ab. Die Suche nimmt die aktuelle GPS-Position des Gerätes als Parameter, durchsucht alle Google Places-Einträge nach dem Suchbegriff, filtert auf die geographisch nahen Einträge und stellt diese nach ihrem User-Ranking geordnet dar. Und (selbst ausprobiert): es funktioniert.
Natürlich ist diese Art der Suche aktuell noch relativ weit entfernt davon, auch Antworten auf komplexe fachliche Fragestellungen geben zu können. Aber auch dabei können ein paar weitere Jahre Entwicklung zu erstaunlichen Ergebnissen führen.
Populäre Mißverständnisse
Obwohl die Fähigkeiten zur Erkennung von Begriffen, Fragestellungen und Kontexten in den Suchmaschinen schon ein erstaunliches Niveau erreicht haben, kommt es dennoch immer wieder zu Mißverständnissen und falschen Zuordnungen. Typischerweise ist das der Fall, wenn Begriffe mehrere semantisch korrekte Bedeutungen haben, die von einer Suchmaschine auch durch den Kontext nicht sinnvoll aufgelöst werden können. Ein schönes Beispiel für diese Begriffsambiguität zeigt folgendes populäre Twitter-Mem:
Sprachgesteuerte Assisenten: die Suche ohne Trefferliste
Noch einen Schritt weiter gehen Anwendungen, bei denen die Suche nur noch als eine Funktion von vielen in einen sprachgesteuerten Assistenten integriert wird. Bei Assistenten wie Siri, Google Now oder Cortana wird die Suche dabei noch auf einem Smartphone oder Desktop ausgeführt und kann mit anderen Applikationen verzahnt werden. Geräte wie Amazon Echo gehen noch weiter und realisieren Hardware, bei der sowohl die Frage als auch die Antwort nur noch über ein Sprachinterface erfolgt, weil das Device gar kein Display mehr für die Ausgabe besitzt.
Wird eine Suche ausgeführt, wirken ähnliche Algorithmen wie bei der Suche mit einer Frage in einem Desktop-Browser – doch das Paradigma der Ausgabe ist ein völlig anderes: Hier geschieht letztlich nicht mehr und nicht weniger als die Abschaffung der Trefferliste. Der Nutzer stellt eine Frage und erhält eine Antwort – und in der Regel: genau eine Antwort. Ab und zu (wie z.B. bei der Alexa-Suche nach Produkten), wird noch eine zweite Variante angeboten. Aber Trefferlisten sind in diesen Suchsystemen Geschichte.

Amazon Echo und die integrierte Assisentin “Alexa”: Die nächste Evolutionsstufe der Suche? (Quelle/Copyright: amazon.com)
Für Anbieter von Content und Produkten hat dies entscheidende Konsequenzen, auf die bereits Online-Marketing-Experte Karl Kratz in seinem höchst lesenswerten Artikel zu digitalen Assistenten hingewiesen hat:
- Die Aufmerksamkeit der Kunden verengt sich noch mehr als bisher auf die Top-Treffer. Wo bereits bei der Desktop-Suche kaum jemand mehr die Treffer auf der zweiten Seite anschaut, ist dies in der Sprachausgabe schlicht nicht mehr praktikabel. Gleichzeitig wird direktes SEO schwer bis unmöglich, weil die Assistenten nahezu nie Informationen über ihre Auswahlkriterien mitgeben.
- Die Abhängigkeit von der Integration in die Apps der großen Ökosysteme wird höher – und gleichzeitig auch die Wahrscheinlichkeit, dass der Nutzer zwar Informationen von einem Content-Anbieter erhält, aber nie dessen Seite besucht, weil der Content von der Assistenten-App nur weiter aggregiert wird.
- Die Anforderungen an passgenaue Integration für Content- und Produkt-Anbieter steigen. Die Inhalte müssen genau so strukturiert sein, dass die Algorithmen sie auch optimal auswerten können. Aber auch inhaltlich bekommt bei diesem Paradigma nur solcher Content auch Relevanz, der direkt auf eine Frage oder ein Bedürfnis des Nutzers antwortet. Dazu muss man die Fragen und die Begriffswelt seiner Kunden sehr gut kennen – und auf sie reagieren.
Die vielen aktuell in den Medien verbreiteten Beispiele für Fehlentscheidungen solcher Assistenten-KIs (z.B. die versehentlich ausgelöste Einkaufswelle durch den Sprachbefehl “Alexa, buy me a dollhouse”) zeigen, dass diese Systeme momentan noch in den Kinderschuhen stecken. Und auch darüber hinausgehende Anwendungen wie die Alexa Skills oder die Sprachbefehle von Google Now sind zwar bereits in großer Zahl implementiert, aber in der Praxis oft noch sehr unhandlich für den Nutzer. Aber sie zeigen, wohin die Entwicklung hingeht: weg vom Eintippen per Tastatur – und weg von der Trefferliste.
Die nächste Stufe: Visuelle Suche mit Google Lens
Auf der diesjährigen Google I/O wurden die aktuellen Entwicklungen und die Roadmap von Google in einer Keynote von Sundar Pinchai vorgestellt; breiten Raum nahm dabei das Thema Virtual Reality ein. Aber auch eine ganz bemerkenswerte Innovation berührt das Thema Suche: die Einführung der visuellen Suche über Google Lens. Über Anwendungen wie die Suche nach ähnlichen Fotos in der Google-Bildsuche oder das OCR-Interface für Google Translate (Text fotographieren, Übersetzung direkt ins Bild eingeblendet bekommen) hat Google bereits viel Erfahrung in der Bild-Analyse und Verarbeitung (und nahezu unendliche Mengen Datenmaterial für das Training der visuellen Algorithmen).
Aber Google Lens geht noch einen Schritt weiter und schafft de facto ein visuelles Interface für die Google-Suche, das direkt in die Kamera-App integriert werden kann. In der Keynote wurden folgende Use Cases gezeigt, die klar das Potenzial von Lens zeigen: Bei einem Foto einer Blume erkennt das System die Spezies und kann damit Google-Suche, Wikipedia oder Fachdatenbanken ansteuern. Bei einem Foto einer Restaurant-Fassade wird Google Maps/Places abgefragt und der Places-Eintrag mit den User-Rankings direkt ins Bild geblendet. Aber auch sinnvolle Aktionen aufgrund des Bildinhalts werden bereits erkannt: Beim Fotographieren eines Router-Access-Code erkennt die Bildanalyse nicht nur den Code an sich, sondern loggt das Gerät direkt ins dazugehörige WLAN ein.
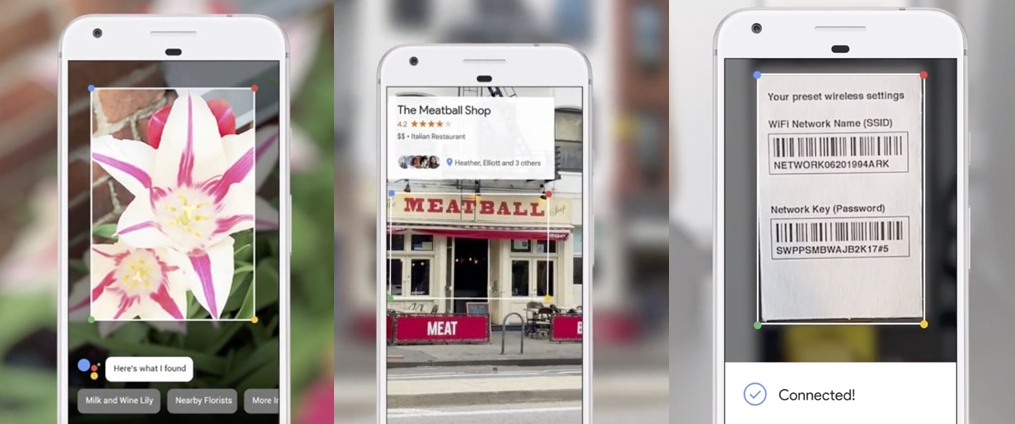
Google Lens: Fortgeschrittene Bilderkennung – mit nachgelagertem, automatischem Funktionsaufruf (Quelle/Copyright: google.com)
Auch in diesem Fall sind aus dem Stand heraus zahlreiche sinnvolle Anwendungsfälle vorstellbar. Ein visuelles Suchinterface hat durchaus das Potenzial, die gewohnte Keyword-Suche in bestimmten Bereichen vollständig obsolet zu machen. Denn wie die oben erwähnten Use Cases zeigen, ist es oft relativ einfach für eine App, eben nicht nur eine Suche anzustoßen, sondern aus dem Bild und dem situativen Kontext darauf zu schließen, welche weiteren Aktionen im Anschluß sinnvoll sind – wie z.B. bei einem Router-Passwort der Login ins dazugehörige Netzwerk – und diese auch gleich auszuführen.
Es bleibt spannend – für alle Content- und Produkt-Anbieter im Netz
Vor allem die Entwicklung im Bereich sprach- und bildgesteuerter Suche zeigt deutlich, wie weit sich Content-Zugang in vielen Bereichen bereits vom Paradigma der “klassischen” Google-Suche entfernt hat. Die Bedeutung der Suchseite von Google sinkt dadurch tendenziell – aber Google als Gesamtunternehmen beweist durch seine Fortschritte bei Sprachsuche und Foto-Auswertung erst recht seine Technologieführerschaft.
Für Anbieter von Content und Produkten wird es dabei umso zentraler sein, diese Entwicklungen gut zu beobachten und dabei stets zwei Fragestellungen im Blick zu haben:
- Wie kann ich sicherstellen, dass meine Inhalte auch im nächsten Such-Paradigma optimal gefunden werden können? Was muss ich für meine eigene Sichtbarkeit tun, um nicht völlig von den großen Ökosystemen als Gatekeeper abhängig zu sein?
- Wo werden Kunden auch in meinen eigenen Applikationen Such-Funktionen der nächsten Generation erwarten und wann? Was muss ich dafür in der Technologiebasis, im Content und in den Content-Zugängen tun, um absehbaren Kundenerwartungen gerecht zu werden?
Denn sicher ist in diesem Bereich nur eines: Mit Alexa und Lens wird die Evolution der Suche nicht enden.
Pingback: Google Talk to Books – die Zukunft der Buchsuche? | smart digits