
smart content – wenn die Inhalte sprechen lernen
 Content is king. Aber nur, wenn er auch intelligent genug ist. Denn durch den exponentiellen Anstieg von Informationen ist der direkte Zugang zur situativ relevanten Information wichtig. Diese Orientierung haben Verlage über Jahrhunderte geleistet. Heute brauchen sie neben der redaktionellen Kompetenz vor allem aber die richtige Technologie. Google setzt weltweit die Benchmarks und hat es mit dem Knowledge Graph vorgemacht: Suchmethoden und Mechanismen zur Content-Erschließung boomen. Sie gehen über die Volltextsuche weit hinaus und bieten dem Nutzer zusätzliche Mehrwerte durch semantische Indexierung, Kontext-Verständnis und die Möglichkeit zur Eingabe in natürlicher Sprache. Auf der Google I/O in der letzten Woche wurden dazu neue Funktionen und Ansätze gezeigt, die den Standard der Zukunft zeigen. Und je größer die Informationsmengen, die in Fachgebieten erschlossen werden müssen, umso größer ist der Nutzen solcher Funktionen. Welche Ansätze gibt es momentan bei intelligenten Mechanismen für Content-Zugänge und wie können sie für die Erstellung von Content-Produkten benutzt werden?
Content is king. Aber nur, wenn er auch intelligent genug ist. Denn durch den exponentiellen Anstieg von Informationen ist der direkte Zugang zur situativ relevanten Information wichtig. Diese Orientierung haben Verlage über Jahrhunderte geleistet. Heute brauchen sie neben der redaktionellen Kompetenz vor allem aber die richtige Technologie. Google setzt weltweit die Benchmarks und hat es mit dem Knowledge Graph vorgemacht: Suchmethoden und Mechanismen zur Content-Erschließung boomen. Sie gehen über die Volltextsuche weit hinaus und bieten dem Nutzer zusätzliche Mehrwerte durch semantische Indexierung, Kontext-Verständnis und die Möglichkeit zur Eingabe in natürlicher Sprache. Auf der Google I/O in der letzten Woche wurden dazu neue Funktionen und Ansätze gezeigt, die den Standard der Zukunft zeigen. Und je größer die Informationsmengen, die in Fachgebieten erschlossen werden müssen, umso größer ist der Nutzen solcher Funktionen. Welche Ansätze gibt es momentan bei intelligenten Mechanismen für Content-Zugänge und wie können sie für die Erstellung von Content-Produkten benutzt werden?
Automatisierte semantische Analyse mit Big Data-Methoden
Im Wesentlichen sollen die Google-Dienste möglichst voll automatisiert Daten erschließen durch statistische Methoden und Auswertung großer Mengen von Kundendaten. Zusammen mit Verfahren zur Erkennung von Sinnzusammenhängen wurde zunächst eine Funktion wie der Knowledge Graph möglich. Die nächste Generation von Funktionen wurde nun auf der Google I/O vorgestellt:
- Ein Semantik-Parser ermöglicht es in Zukunft, aus Beiträgen im sozialen Netzwerk Google+ automatisiert Hashtags zur Verschlagwortung zu extrahieren. Mit Hilfe von Bilderkennungs-Algorithmen soll dies auch für Objekte auf Photos und Orte möglich sein.
- Die Spracherkennung aus dem Google Glass-Projekt wird mit dem “persönlichen Assistenten” Google Now und der Suchmaschine verknüpft. So können Anfragen in natürlicher Sprache an die Suchmaschine gestellt werden, die je nach den Nutzerdaten in Google Now noch kontextabhängig ausgewertet werden.
- Durch das Redesign von Google Maps und die neu integrierten Geo-APIs können auch Geodaten des Nutzers stärker in diese kontextabhängige Verarbeitung einbezogen werden: So wird die Nähe zu bestimmten Orten den Kontext beeinflussen oder die Art der Bewegung des Nutzers mit ausgewertet. Die Kombination von aktueller Position und persönlichem Terminkalender ermöglicht Funktionen wie Stauhinweise oder die Anzeige von benötigten Fahrplänen, ohne dass der Nutzer dies explizit anfordern muss.
Alle Funktionen dieser Art haben jedoch gemeinsam: Sie sind nur sinnvoll realisierbar auf Basis der Aggregierung immenser Datenmengen und benötigen einen Anwendungskontext, der genügend Nutzerdaten für den persönlichen Kontext verfügbar macht. Dazu werden sie umso besser, je mehr Dienste der Kunden nutzt und je mehr Daten sich dadurch vernetzen lassen. Bei Google ist das kein Problem. Aber wie kann man vorgehen, wenn man nicht über ein so komplexes Ökosystem mit alle notwendigen Daten verfügt?
Fachbezogene semantische Ontologien
Einen anderen Ansatz für semantische Erschließung in hochspezialisierten Fachgebieten zeigt das Inquire-Projekt: Für das universitäre Lernen in stoffintensiven, komplexen Naturwissenschaften wie Medizin, Biologie oder Chemie wurde hier ein Experten-System geschaffen, in dem auf Basis einer Wissens-Datenbank und einer Semantik-Engine ganz neue Funktionen zur Lernunterstützung realisierbar sind: Intelligente Glossare mit vielfältiger Verlinkung, Eingabemöglichkeit von Fragen in natürlicher Sprache und selbständige Generierung von Vertiefungsfragen auf Basis des Content bieten Lernmöglichkeiten, die einen echten Qualitätsunterschied gegenüber früheren Anwendungen ausmachen.
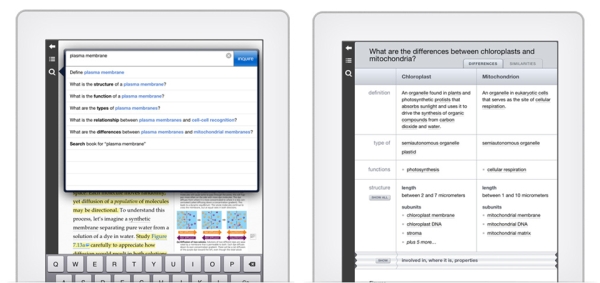
Eingabe von Fragen und Repräsentation von Konzepten in Inquire
Diese Erschließungstiefe hat jedoch einen grundlegenden Nachteil bei der Erstellung von Produkten: Damit die Semantik-Engine diese Funktionen realisieren kann, müssen alle dazu notwendigen Konzepte in einer geeignet strukturierte Knowledge-Base angelegt und verknüpft werden. Inquire verwendet dabei in seiner Autoren-Umgebung ein Verfahren, bei dem jeder Satz der Publikation über eine graphische Bedienungsoberfläche in seine zentralen Konzepte zerlegt und mit den notwendigen semantischen Zusammenhängen versehen wird. Diese Vorgehensweise gewährleistet eine hohe Content-Qualität, ist aber bei umfangreicheren Datenmengen auch mit erheblichen Aufwänden für die Aufbereitung verbunden und dürfte sich ausschließlich für Produkte mit sehr hohem Wertschöpfungsgrad lohnen.
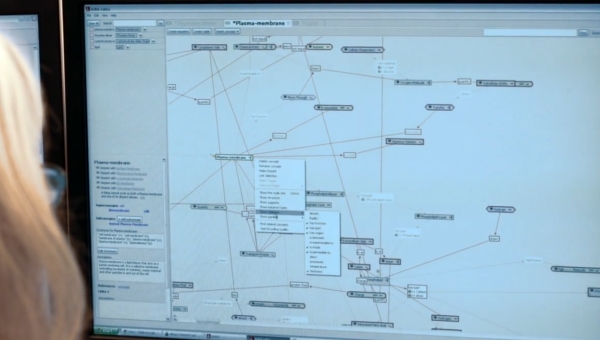
Content-Strukturierung über die Autorenumgebung von Inquire
Kombination von verschiedenen Ansätzen
Für Verlagsprojekte und die Anforderungen der meisten kleineren und mittelgroßen Content-Anbieter dürften beide Ansätze in der Reinform kaum realisierbar sein. In der Praxis hat sich deswegen für die meisten Anwendungsfälle eine einfacher implementierte Mischung der beiden Methoden als sinnvollster Weg bewährt. In CMS-Umgebungen wie z.B. der L4 Suite von Moresophy wird semantische Strukturierung durch menschliche Eingabe mit automatisiertem Objekt-Tagging auf Basis von Mustererkennung und Fach-Ontologien verknüpft. System-Umgebungen wie Paux zeigen, wie sich auf der Basis von standardisierten Content-Objekten Mehrwert-Dienste für Inhalts-Erschließung und Verteilung in sozialen Netzwerken realisieren lassen. Und mit dem Stanbol-Projekt steht mittlerweile auch eine Open Source-Alternative für semantisches Content-Management im Rahmen der Apache Foundation zur Verfügung. Wie sich auf dieser Basis anspruchsvolle CMS-Projekte auch in kurzer Zeit mit Standard-Komponenten realisieren lassen, zeigen Showcases aus den USA.
Sie wollen mehr wissen?
Wenn Sie solche und ähnliche Techniken für die Konzeption und Erstellung eigener Content-Lösungen nutzen wollen und dafür Know How benötigen, empfehlen wir Ihnen unser Seminar “Smart Content – Intelligente Verlagsprodukte, neue Erlösquellen”, das am 11./12.06. in der Akademie des Deutschen Buchhandels stattfindet. Michael Dreusicke, Harald Henzler und Fabian Kern zeigen hier, wie Verlagsinhalte medienneutral aufbereitet, systematisch mit Mehrwerten für die Online- bzw. Mobile-Nutzung versehen und erfolgreich monetarisiert werden können.
Pingback: Sind Algorithmen die besseren Verleger? | smart digits