

Vor kurzem durften wir erfahren, dass zwar noch nicht die Weltformel, aber doch das Genom von Bestsellern erforscht ist. Künftig werden Verlage also endlich mit viel weniger Büchern viel mehr Geld verdienen. So lustig das klingen mag und so absurd die Ergebnisse der dort vorgelegten Studie sind, dahinter steckt natürlich die Frage, ob man es im Verlagsgeschäft nicht endlich auch schafft, wie Google und Amazon und Facebook die Profile der Kunden und ihrer Bedürfnisse besser zu erkennen. Die Abomodelle von readfy oder Skoobe gehen ja genau in diese Richtung. Um das gut machen zu können, braucht es natürlich Daten. Viele Daten.
Wie man das gut macht, darüber könnten netflix und oyster Auskunft geben.
Netflix ist als Produzent von “House of Cards” nun erstmalig auch aus der Ecke der Distributoren von Filmen und Serien für den Hausgebrauch getreten, ähnlich wie es Weltbild und zuletzt Amazon im Verlagsgeschäft gemacht haben. Interessant ist dabei das Vorgehen: Über Jahre wurden die Filme katalogisiert, aber nicht in der üblichen Weise. Filme wurden in kleinste Contentbausteine zerlegt und mit den verschiedensten Attributen versehen. Dann hat man das Kundenverhalten damit verknüpft und aus der Vielzahl der Puzzlebausteine wieder Rückschlüsse auf das Programm gezogen.
Wichtig ist dabei die Fähigkeit, die richtigen Begriffe zu wählen, um die Filme zu charakterisieren. Denn hier entscheidet es sich, ob man nah am Kundenbedürfnis oder nicht.
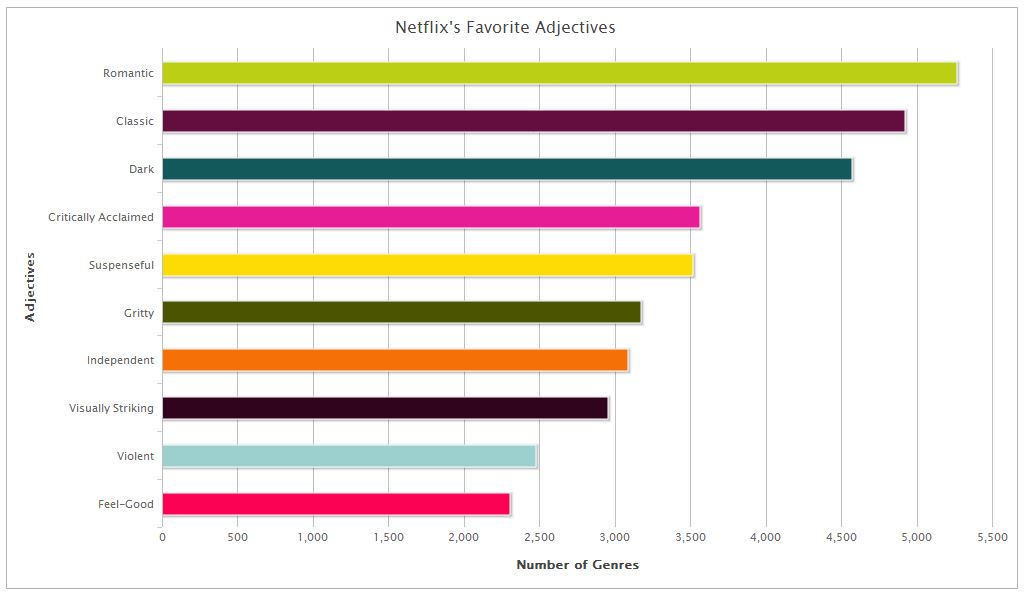
Das Ergebnis sind dann nicht nur die üblichen Auflistungen nach Schauspielern, Orten und Erscheinungsjahr, sondern auch weitere Eigenheiten wie die hier gezeigten. Diese Mischung von kuratiertem Wissen und Algorithmen führt dann erst zu besseren Vorhersagen.

Dabei gibt es eine klare Hierarchie der Begriffe, so dass die Ergebnisse dann auch nicht beliebig werden. Und auch hier zeigt sich die Bedeutung des erfahrenen Kurators: Ein Algorithmus bekommt das alleine nicht hin.
Wenn die eigene Hausarbeiten erledigt sind, d.h. die Qualifizierung der eigenen Daten, dann kommt der Abgleich mit den Kundenanforderungen. Deren Käufe und Bewegungen können dann ganz anders zugeordnet werden, wenn man genau weiß, was sie da gekauft haben.
 Die zahlreichen Abodienste für Bücher wie z.B. Oyster oder Epic! versuchen mit verschiedenen Merkmalen ihre Kunden zu begeistern. Bei Oyster sind es vor allem Design und die Empfehlungen aus dem Netzwerk, bei Epic! will man auch durch die Fülle an Inhalten möglichst nah am Kunden sein. Die Bibliotheken sind deshalb neben Amazon die Hauptkonkurrenten.
Die zahlreichen Abodienste für Bücher wie z.B. Oyster oder Epic! versuchen mit verschiedenen Merkmalen ihre Kunden zu begeistern. Bei Oyster sind es vor allem Design und die Empfehlungen aus dem Netzwerk, bei Epic! will man auch durch die Fülle an Inhalten möglichst nah am Kunden sein. Die Bibliotheken sind deshalb neben Amazon die Hauptkonkurrenten.
In Deutschland versuchen Skoobe und readfy (Schwerpunkt Werbefinanzierung und Flatrate) den Markt zu erobern.
Einen etwas anderen Ansatz versucht Jellybooks, die über kostenlose Leseproben den Kunden an sich binden. Diese können dann über Amazon oder readmill auch einfach gelesen und abgerufen werden.
Die Herausforderungen bestehen deshalb auch darin, die richtigen Kundendaten zu generieren und die Inhalte zu kuratieren (hier die Links zu vorangegangenen Beiträgen hierzu).
Denn: Algorithmen ersetzen die Verleger nicht. Aber ohne deren Kenntnis werden die Verleger der Zukunft Amazon nur hinterherlaufen.
Genau hier setzt auch der im März in Deutschland startende Dienst flipintu ein: Kundendaten werden mit einem aufwändigen Algorithmus verknüpft und sollen so zu einer besseren Auffindbarkeit und Zuordnung von Kundenwunsch und Titeln führen.
Pingback: Big Data: Was macht Sinn für Verlage? | smart digits
Pingback: Abomodelle für Bücher | smart digits
Pingback: King Content – Queen Context | smart digits