

“Big Data” gehört sicherlich zu den am meisten strapazierten Buzzwords der letzten Zeit. Und auch wenn nach Gartner die Technologie ihren Hype-Peak überschritten hat und sich auf den Weg ins Tal der Desillusionierung befindet, gibt es doch valide Anwendungsszenarien für Verlage und Medienhäuser. Und so “Big” müssen die Datensätze in der Praxis gar nicht sein, um nützliche Einsichten in Kundenverhalten zu bekommen und Schlüsse für Produkt-Entwicklung und Portfolio-Pflege ziehen zu können. Das Modell von netflix für die Buchbranche und die Flatratemodelle für Bücher haben wir erst kürzlich erörtert. Aktuell hat der eBook-Distributor Kobo seine Erfahrungen in diesem Bereich in einem Whitepaper veröffentlicht. Wir fassen die wichtigsten Punkte zusammen:
Big Data – don’t believe the hype
Eines der zentralen Kriterien von “Big Data” – die Aggregierung von extrem großen Datenmengen – ist für Publisher in den wenigsten Fällen relevant, einfach weil im Alltagsbetrieb selten Daten in Größenordnungen anfallen wie bei weltweit agierenden Konzernen wie etwa Facebook. Auch Szenarien, die auf Feinst-Optimierung des laufenden Betriebs auf Basis von Echtzeit-Datenauswertung basieren – beispielhaft skizziert für das McLaren-Ingenieur-Team in der Business-Week – dürften kaum jemals auf den Verlagsbetrieb übertragbar sein.
Einige Errungenschaften von Big Data-Analyse-Systemen aber können durchaus sinnvoll adaptiert werden, wie der Big Data-Experte Viktor Mayer-Schönberger auf der diesjährigen Content-Konferenz ausgeführt hat, hier gut zusammengefasst von Marcello Vena. Zentrale Vorteile der Analysetechniken sind beispielsweise:
- Zusammenfassung von unstrukturierten und heterogenen Daten aus verschiedenen Quellsystemen
- Aggregierung von Erkenntnissen aus der gesamten Wertschöpfungskette, z.B. von Verkaufsdaten aus ERP-Systemen, Traffic-Analyse aus der Web-Präsenz, Social-Media-Statistiken und Nutzungsdaten aus Lese-Systemen
- Erfassung von Clustern und Korrelationen in den Daten ohne die Notwendigkeit, mit fest formulierten Fragestellungen und Hypothesen an die Analyse heranzugehen.
Besonders gute Voraussetzungen für neue Erkenntnisse haben dabei Anbieter, die beispielsweise Verkaufszahlen direkt mit der Nutzung der Inhalte korrelieren können. Der eBook-Distributor Kobo gehört zu diesen Anbietern und ist für einen verhältnismäßig offenen Umgang mit den eigenen Daten bekannt. Das frisch veröffentlichte Whitepaper “Publishing in the Era of Big Data” ist lesenswert – die darin skizzierten Auswertungs-Szenarien für Verkaufs- und Nutzungsdaten sind z.B. folgende:
Versteckte Stars identifizieren
Ein Szenario fasst Titel mit mittlerem Verkaufsrang zusammen und korreliert die Verkaufszahlen mit dem Leserengagement, gemessen an der Menge der Leser, die den Titel tatsächlich zuende gelesen haben (bzw. wenn nicht – bis zu welchem Anteil). Der Cluster der Titel, die viel gelesen, aber wenig verkauft werden, könnte aus “versteckten Stars” bestehen – Titel, die Leser offenbar bewegen und bei denen eventuell auch die Verkäufe gesteigert werden könnten, wenn hier gezielt in Marketing investiert würde. Stünden für diese Titel ggf. noch Kampagnendaten oder Social-Media-Auswertungen zur Verfügung, wäre eine Statistik dieser Art ideal zur Validierung der Marketing-Strategie.
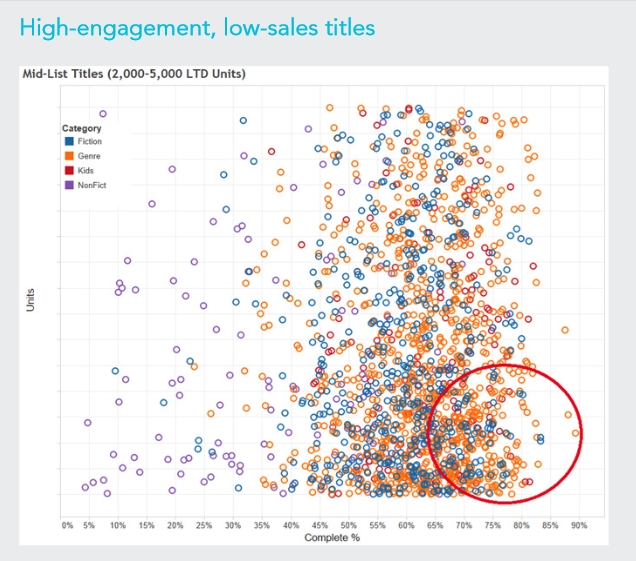
Auswertung des Portfolio mit hohem Nutzungsanteil, aber geringen Verkäufen (Quelle: Whitepaper “Publishing in the Era of Big Data” / Copyright: Kobo)
Den Erfolg von Serien und Reihen validieren
Ein weiteres Szenario widmet sich einer Roman-Serie und vergleicht Verkaufszahlen über die Titel mit dem Leser-Engagement. Wenn der Befund wie in diesem Beispiel zeigt, dass zwar die Verkäufe einigermaßen stabil bleiben, aber das Leser-Engagement stetig abnimmt, wäre dies ein klares Zeichen, dass ein Lektorat hier strategisch eingreifen muss: Vielleicht ist es Zeit, die Serie zu einem Ende zu bringen, vielleicht muss der Autor von einem anderen Handlungsverlauf überzeugt werden, vielleicht stimmt etwas in der Serienaufteilung nicht?
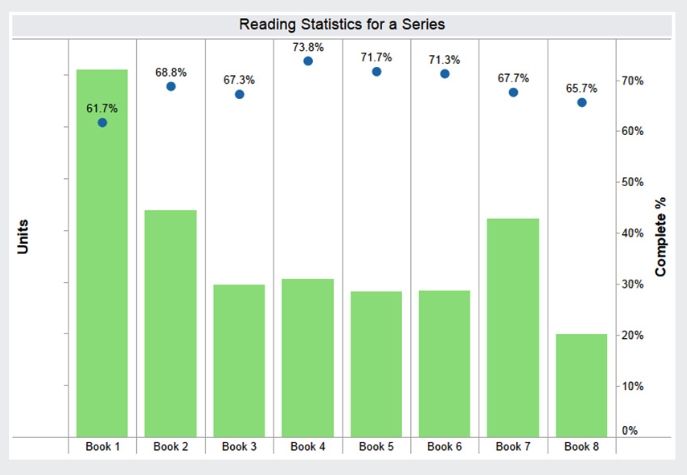
Korrelation von Verkäufen und Leseanteil für eine Titel-Serie: Was tun, wenn das Engagement immer mehr abnimmt? (Quelle: Whitepaper “Publishing in the Era of Big Data” / Copyright: Kobo)
Was tun, wenn Stars versagen?
Ein weiteres, spannendes Szenario vergleicht die Performance zweier Literatur-Preisträger und ihrer Titel: Obwohl beide in erheblichem Maße vom Preis und dem dazugehörigen Marketing profitiert haben, unterscheiden sich Verkaufszahlen und Leser-Engagement deutlich. Was würde man in der Programmentwicklung an dieser Stelle tun? Mehr Marketing in den schwächeren Titel stecken, um ihn zu stärken? Oder im Gegenteil, alles auf den stärkeren Titel setzen und sich eventuell vom schwächeren Autor trennen?
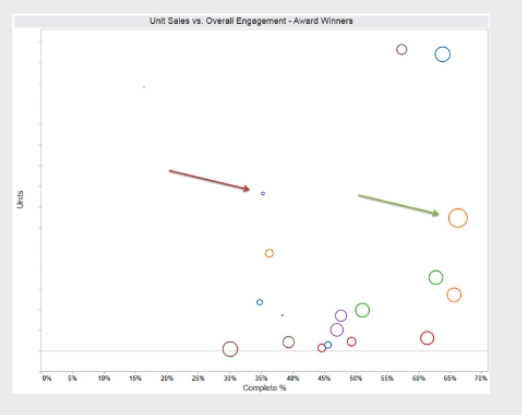
Vergleich von Literaturpreisträgern: Was tun im Programmbereich, wenn sich die Performance der Titel deutlich unterscheidet? (Quelle: Whitepaper “Publishing in the Era of Big Data” / Copyright: Kobo)
Chancen und Herausforderungen
Die beschriebenen Szenarien aus der Kobo-Studie zeigen sehr deutlich, wie tiefgehend die Einblicke in ein Programm-Portfolio sein können, wenn auch nur Verkaufs- und Nutzungsdaten miteinander in Bezug gesetzt werden können. Zu ganz ähnlichen Schlussfolgerungen kam auch ein Workshop zu Nutzerdaten auf der diesjährigen e:publish-Konferenz, bei dem DeGruyter und MarkStein ein vergleichbares Modell der Korrelation von Verkaufs- und Nutzungsdaten live zeigten.
Doch für die meisten Verlage dürften die Herausforderungen solcher Ansätze zunächst überwiegen:
- In den allermeisten Fällen sind im Haus zwar Verkaufsdaten, vielleicht auch Social Media- und Web-Analytics, vorhanden, aber keine Nutzungsdaten für die Inhalte.
- Obwohl der Einsatz von Analyse-Systemen aus der Big Data-Welt mittlerweile weit weniger Ressource erfordert als noch vor einigen Jahren, ist die mentale Hürde für Projekte dieser Art immer noch hoch.
- Bei der Interpretation der Analysen ist immer eine Herausforderung, dass die ermittelten Korrelationen alleine zunächst nicht unbedingt eine Aussage über die zugrundeliegenden Kausalitäten ergeben.
Empfehlungen an Verlage, die von Big Data-Analysen profitieren wollen, können dagegen sein:
- Wenn man die Daten nicht selber sammeln kann, mit Partnern zusammenarbeiten: Gerade in Einblicken in das Nutzerverhalten kann der große Gewinn einer Kooperation mit Anbietern wie Sobook, Skoobe, Readfy, Kobo oder Flipintu bestehen – auch wenn sich die Erlöse an sich in Grenzen halten.
- Klein anfangen, validieren, verfeinern: Wer jahrelang an einem Datenbankprojekt für Big Data feilt, kann sich sicher sein, dass es am Ende am Bedarf vorbei geht. Wie in der agilen Entwicklung gilt es, schlanke Szenarien für zugespitzte Fragestellungen umzusetzen, diese schnell an der Realität zu testen, und per Iteration zu verfeinern.
- Keine Angst vor Daten: Auch wenn Datenanalyse hierzulande spätestens seit dem NSA-Skandal nicht den allerbesten Ruf hat – sensibel und verantwortungsbewußt eingesetzt, beinhalten Big Data-Analysen am Ende große Chancen für ein besseres Angebot.
Pingback: Computer lernen schreiben und denken – kognitive Systeme | smart digits
Pingback: Mobile Publishing: Update Oktober/November 2014 | smart digits
Pingback: Die Woche im Rückblick 14.11. bis 20.11.2014 | sevblog - Self-Publishing und Schreiben
Pingback: Big Data: Was macht Sinn für Verlage? | sm...