

KI macht Angst. Maschinen können „besser“ denken als wir, die wir doch aufgrund unseres Denkens diesen Planeten beherrschen? Und jetzt kommen lauter fleißige Softwareprogramme, die schneller lesen, analysieren und neu kombinieren. Diese Helferlein werden Metadatenmanagern unter die Arme greifen und ihre Arbeit in Zukunft prägen. Denn sie sind auf Dauer günstiger und vor allem genauer. Wir müssen deshalb versuchen sie zu verstehen, damit wir die Werkzeuge richtig einsetzen. Ein Messer kann man zum Töten oder Schneiden von Gemüse nutzen. Wir würden den Gebrauch nie grundsätzlich verbieten wollen, aber die richtigen Regeln für den Umgang entwickeln wir nur, wenn wir wissen, was ein Messer kann und was nicht.
Metadaten zu managen ist im limbischen System des Menschen tief verankert
Wir leben von der Reduktion der vielen Informationen auf einige wenige. Unsere Sinne nehmen über 1 Millionen Informationseinheiten pro Sekunde auf. Diese werden in unserem Gehirn weitestgehend automatisiert abgespeichert, ohne dass wir das auf den ersten Blick merken. Unser Bewusstsein erhält nur die wichtigsten Schlagwörter zugespielt, nämlich die, die uns anscheinend am meisten geprägt haben und interessieren. Wir überleben durch diese Reduktion, weil wir sonst zu langsam wären in Krisensituationen und im Handeln.
Wenn man so will, hängt unser Überleben davon ab, dass unser Gehirn die wesentlichen Informationen herausfiltert und so emotional belegt, dass wir ihre Relevanz sofort erkennen: Ein Lächeln kann Zuneigung, Freude oder Spott ausdrücken, je nachdem ob es von der Geliebten, einem Kind oder einem Folterer kommt. Und wir überleben, je besser wir die tausend Möglichkeiten der Interpretation beherrschen.
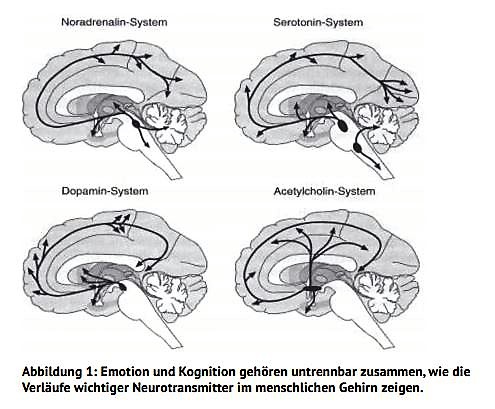
Die Analysen von H.G. Häusel zeigen, dass wir nicht ohne Emotion denken – wir speichern unsere Informationen immer “subjektiv” und prägen unsere Sinneseindrücke je anders im Großhirn ein. Zum Hintergrund siehe z.B. diesen Aufsatz von H.G. Häusel. (Quelle: H.G. Häusel)
Wenn wir Metadaten zu unseren Produkten vergeben und auf eine entsprechende Reaktion unserer Kunden hoffen, so bauen wir hier mühsam einen ähnlichen Prozess ab. Aber wir sind stolz darauf, weil wir immer stolz sind auf unser Großhirn. Wenn jetzt digitale Helferlein für uns die besseren keywords heraussuchen und mit dem Suchverhalten unserer Kunden in Sekundenschnelle abgleichen, dann ist das zunächst so, als ob ein Rivale im ureigensten Revier auftaucht. Wenn wir uns aber darauf beschränken, diesen Rivalen richtig einzusetzen und nicht als Rivalen betrachten, können wir gewinnen. Um welche Tools geht es?
Wozu digitale Werkzeuge im Metadatenmanagement?
Bücher sind wunderbare Anschauungsmaterialien für das Funktionieren von Metadaten im Netz. Denn Informationseinheiten haben wir dort mehr als uns lieb sind. Wir wollen aber doch nur den einen, für uns relevanten Treffer und nicht in der Informationsflut ertrinken. Also halten wir uns an die bekannten Suchbegriffe, sprich Metadaten. Autor und Titel sind noch relativ klar, ebenso das Genre. Und dann sind noch der Preis und die Ausstattung, das Cover und die Haptik, vielleicht auch noch Verlag und Umfang relevant und ein paar weitere Merkmale. Daran haben wir uns gewöhnt und das sind die etablierten Standards, um Bücher auffindbar zu machen.
In einer Welt mit wenigen Büchern und einer hohen Nachfrage wäre das auch kein Problem: Aber wir leiden unter einem Überangebot und jetzt will nicht mal mehr IKEA Bücher zur Dekoration in seinem Katalog abbilden (zur Erinnerung: 2011 zeichnete sich das mit der Einstellung des Billy-Regals leider schon ab und wir berichteten damals). Wie also machen wir unsere Bücher überhaupt noch sichtbar angesichts der Übermacht von netflix und spotify?
Die Kür wird jetzt zur Pflicht: Man muss die Metadaten finden, die just in dem Moment der Suche den Kunden genau ansprechen. Wo finden wir diese?
Wo finde ich die richtigen Metadaten?
Die Empfehlung
Cherche la femme! Der Mord entsteht aus Nähe und Leidenschaft – also suchen Sie im Umfeld der möglichen Leser nach deren Gewohnheiten und Vorlieben. Bücher werden meist empfohlen und dann gelesen. Freunde und Verwandte haben dabei viel Gewicht, denn das ist die wichtigste “peer group”. Wir hören auf die Meinungen derer, die uns nahe sind, und wir wollen ja schließlich mit jedem Buch auch den Anschluss an unsere Gemeinschaft sicherstellen. Bei Amazon würde das in der folgenden Form dargestellt werden: “wird Ihnen persönlich von jemandem empfohlen, dessen Meinung Ihnen wichtig ist”. In der Sprache der Metadaten ausgedrückt wären das drei Felder:
- “empfehlende Person”
- “Einfluss dieser Person in Bezug auf Buchempfehlungen”
- “Bewertung des Buchs selbst durch die empfehlende Person”

Lesen selbst ist zwar ein einsamer Akt, aber der Antrieb zur Lektüre hat auch immer einen Bezug zu den Mitmenschen. Man liest etwas, weil es in Bezug auf die Umwelt wichtig, erhellend, beflügelnd ist. Das Gelesene dient auch dazu, andere zu belehren, beeindrucken, verführen – seinen eigenen Ort in der Gemeinschaft besser zu finden.
Es liegt auf der Hand, dass die sozialen Netzwerke relevant sind für alle drei Felder: Die empfehlenden Personen nennen wir dort Influencer, den Einfluss selbst messen wir in Click-rates und likes und die Bewertung selbst können wir durch semantische Analysen filtern.
Das dafür nötige Toolset kennen wir aus dem Marketing. Es ist ein Dashboard mit der Abbildung der Vorlieben unserer Kunden in den verschiedensten Netzwerken. Hier sind digitale Werkzeuge nötig, denn niemand kann (und will!) alle Einträge aus den Netzwerken wirklich lesen. Wir brauchen hier die Verdichtung von Interessen und keywords, um gezielt dann das auszuwerten und zu lesen, was im Zusammenhang mit unserem Angebot wichtig ist. Das ersetzt nicht den persönlichen Austausch, aber muss ihn begleiten, um dem Kunden auch in der digitalen Welt so nahe wie möglich zu sein. Goodreads wurde nicht ohne Ziel von Amazon gekauft und die Verlage im deutschsprachigen Raum gründen nicht ohne Hintergedanken Lesekreise, Portale für Blogger oder Plattformen mit einer direkten Kundenansprache.
Die Suche
Bei der Suche im Netz sind wir ehrlicher als in Gesprächen, denn wir wollen sofort das, was uns wirklich interessiert. Deshalb können wir aus dem Suchverhalten der Kunden auch vieles für die Auswahl unserer Metadaten ableiten. Hier genügt es, die richtigen Keywords zu platzieren und mit dem eigenen Titel zu verknüpfen. Die thema-Felder sind ein sehr gutes Gerüst, um möglichst alles im Blick zu haben. Bei Ratgebern und Sachbüchern ist es auch relativ einfach. Hier können wir aus dem Thema einiges ableiten. Aber auch dort müssen wir meistens dem Kunden auf den Mund schauen und sind meistens überrascht, dass auch Juristen und Ärzte nur Menschen sind und auf Google nicht immer ihre Fachbegriffe eingeben. Neben dem klassischen Thesaurus brauchen wir auch hier einen genauen Blick auf die wirklichen Suchvorgänge.
Und auch hier können wir auf die Erfahrungen im Onlinemarketing zurückgreifen. Ein klassischer Keywordplaner macht nichts anderes, als auf die Metadaten zu setzen, die seine Kunden wohl anlocken werden. Das Toolset für Onlinekampagnen lässt sich fast 1:1 übertragen. An der Entwicklung der letzten Jahren von einer Gesprächsrunde zum programmatic advertising kann man erkennen, wohin die Reise für Metadatenmanager hingeht.
Wenn wir im Internet suchen, wollen wir schnell auf den Punkt kommen. Deshalb sind schnelle, eindeutige und relevante Ergebnisse eine Belohnung für uns. Dazu brauchen wir aber die richtigen Metadaten. Denn ob wir Spannung, Erotik oder anspruchsvolle Argumente suchen, ist ein großer Unterschied. Wer sich bei den Suchergebnissen vorne präsentiert ist im Vorteil. Spannung ist eben nicht Spannung.
Schwieriger wird es, wenn man nicht genau weiß, wonach der mögliche Kunde wohl sucht, so wie in der Belletristik.
Denn oft wartet man nicht auf die Empfehlungen anderer, weil man tatendurstig selbst in die Welt hinausblickt. Man will Entdecker sein, Flaneur, sich bewusst vom heimischen Herd wegbewegen und das Buch verheißt eine Auszeit aus dem Bekannten. Jetzt zählen Schaufenster, BuchhändlerInnen und Empfehlungen.
Die Metadaten sind hier schwer zu erfassen, denn sie bestehen ja gerade darin, so auf Neues zu deuten, dass es sich von Bekanntem abhebt. “Dieses Buch von Ondaatje ist wie die Bücher von Naipaul geprägt von der Erfahrung der Heimatlosigkeit in fremden Kulturen, aber…”.
Amazon behilft sich hier mit “Bücher, die auch geklickt oder gekauft oder bewertet wurden”. Man deutet durch das Verhalten der Kunden auf mögliche Verwandschaften bei den Inhalten – und kann dabei zwar auf die Trägheit der Masse setzen und zugleich völlig daneben greifen. Das Problem dabei: Die Lust am Suchen und Finden fehlt (neben der semantischen Analyse der Inhalte). Hier hilft nur eine Kombination von Dashboards aus dem Keywordadvertising und einer semantischen Analyse dessen, was in den sozialen Netzwerken auftaucht. Und das wird immer eine individuelle Analyse sein (mein Programm, meine Kunden) und im besten Fall mit einem Abgleich zu anderen Verlagen (wie nahe bin ich dran im Vergleich).
Und die Zukunft? Suchen wir nur noch per Foto oder sprechen wir unsere Wünsche laut aus?
Interessant sind Verfahren, die nicht nur einen Suchbegriff analysieren (“keyword-planer”) und Äußerungen in den sozialen Netzwerken (“touchpoint-Management”), sondern sofort Bezüge zu den Inhalten der Bücher herstellen können, weil sie diese im Volltext vorliegen haben. Googles “Talk to books”, siehe hierzu unseren Beitrag, ist das ambitionierteste Projekt im Zusammenhang mit Metadaten und Buchsuche. Hier wird Büchern als Speicher von Wissen noch eine hohe Bedeutung zugeschrieben. Denn eine Frage wird nicht klassisch “gegoogelt”, sondern nur Bücher werden gefragt. Was auf den ersten Blick seltsam anmutet (“Wieso jetzt den Zugang zu vielen Informationen wieder reduzieren auf wenige Quellen?”) erweist sich beim zweiten Blick als sinnvoll: Das Netz ist zu unübersichtlich, Bücher haben zumindest eine Kuratierung hinter sich und jemand, der ein Buch geschrieben hat, hat nachweislich mehr Zeit investiert und ein Thema systematischer dargestellt als andere. Das sagt immer noch nichts über die Qualität der Inhalte aus, stellt aber eine höhere Hürde dar als Katzenfotos zu posten. Durch eine semantische Analyse kann der Text genauer bestimmten Suchbegriffen zugeordnet werden. Dabei spielen nicht nur die oben erwähnten keywords eine Rolle, sondern auch eine Bewertung der Haltung, die darin zum Ausdruck kommt. Gemeinhin wird dies mit dem Schlagwort “Sentimentanalyse” beschrieben, um zu erkennen, welche Stimmungen und Ansichten durch die Verwendung der Begriffe in einem bestimmten Kontext wiedergeben. Und hier ist es natürlich hilfreich, auf viele Daten zurückgreifen zu können. Bücher bieten die ideale Fingerübung. Was hier erforscht wird, kann in vielen anderen Segmenten genutzt werden, wie z.B. in diesem von der EU geförderten Incubator ausgeschriebenen Pitch zur “Sentimental analysis in consumer journey”. Wenn man die Haltung eines Nutzers gut und schnell erfassen kann, lassen sich dann auch die entsprechenden Angebote viel besser platzieren, von der Werbung bis zum Kauf. Start-ups wie summarizebot können jetzt schon relativ genaue Zuordnungen herstellen zwischen keywords und Stimmungen.
Aber wie wird sich das alles verändern, wenn wir künftig von Alexa, Siri oder Cortana die Antworten ins Ohr geflüstert bekommen? Bradley Matrock sieht “voice-first” als die Zukunft der Buchbranche, weil wir die mütterliche Stimme auch vor allen anderen Kulturinstrumenten wie Tastatur, Stift oder Bildschirm erfahren. Ganz gleich, ob man diese Sicht teilt: Der Vormarsch audiovisueller Medien ist mit netflix, spotify und Co. jedem sofort klar.
In unserem Beitrag über neueste Trends haben wir auch die Zukunft der “visuellen Suche” beleuchtet, die ähnliche Herausforderungen bringen wird. Wenn eine Kamera ein Bild dechiffriert und das dazu passende Angebot im Shop anzeigt, dann geht das zum einen über Metadaten, zum anderen über visuelle Mustererkennung.
Offen ist dabei, ob das auch die Metadaten selbst verändern wird. Denn noch wissen wir nicht, ob Nutzer sprechend andere Begriffe verwenden als schreibend. Auf den ersten Blick nicht, aber wir wissen alle, dass wir anders sprechen als schreiben und alleine die Autocomplete-Funktion muss anders gedacht werden bei der mündlichen Eingabe von Befehlen. Und in der Regel ist der Kontext beim Schreiben ein anderer als beim Reden. Und der Kontext prägt die Suchbegriffe und Intentionen. Und diese Analyse von Kontext und Intentionen der Nutzer wird sich in den nächsten Jahren deutlich verbessern, so dass Empfehlungen auch besser werden.
Diese und andere Themen müssen zusammen bedacht und diskutiert werden. Der Data Summit am 28. November ist mittlerweile im dritten Jahr ein solcher Treffpunkt. Dieses Jahr stehen vor allem die folgenden Fragen im Fokus:
– Wie entwickle ich mein Wissen über meine Zielgruppen weiter? Björn Wagner von “Die Zeit” zeigt, wie man mit den vielen Daten das eigene Angebot besser entwickelt.
– Wie können wir unsere Metadaten zu unseren Produkten optimal auch in anderen Bereichen einsetzen? So können wir z.B. neue Portale so entwickeln, indem wir auch hier thema und das Raster anwenden wie bei den Büchern. So ist sichergestellt, dass wir die Sichtbarkeit nachhaltig verbessern. Tobias Streitferdt von Holtzbrinck wird ein neu gelaunchtes Portal vorstellen, bei dem die thema-Kategorien genutzt wurden.
– Wie können wir die Verwendung der Metadaten in den verschiedenen Shops und anderen Systemen erfassen, über die unsere Kunden nach uns suchen? Und wie sollte ein Dashboard aussehen, das die Steuerung ermöglicht? Henning Schönenberger von Springer Nature stellt ein soeben fertiggestelltes Monitoring-Tool vor.
– Wie sieht die Zukunft von Standards aus und wie sind die Pläne bei editeur und anderen? Graham Bell von editeur wird in einer round-table-Session darüber berichten.
– Wie wird künftig KI eingesetzt und welche Potenziale ergeben sich hierbei? Stefan Herbert von IBM berichtet zum Stand von Watson und der Industrie und Hermann Eckel von tolino und Dmitry Nedovis von summarizebot stellen die Zusammenarbeit eines start-ups mit einem etablierten Unternehmen dar.
– Wie können wir aus den Erfahrungen lernen und die Veränderungen so gut wie möglich umsetzen? Siehe hierzu vor allem die round table-Sessions und Vorträge von Karin Schmidt-Friderichs, Verlag Hermann Schmidt, sowie Sandra Schüssel, mvb, und der Sprecher der IG Produktmetadaten, Dr. Detlef Bauer, libri, und Marion Seelig, Ullstein.
Pingback: Die Woche im Rückblick 09.11. bis 15.11.2018 - Wieken-Verlag Autorenservice