

Zwei der Buzzwords in der Verlagsszene lauten “Big Data” und “discoverability”. Da kommt der Data Summit im November zum richtigen Zeitpunkt. Als Beleg nur drei von vielen Artikeln dieser und der letzten Woche: Anders Breinholst nennt “Discoverability the new king of publishing”, Troy Lambert bricht eine Lanze für Big Data und den Nutzen für Autoren und Leser und O`Leary hat die Argumente auf den Punkt gebracht, warum Verlage auf mobile setzen müssen, egal ob sie gedruckte oder digitale Produkte verkaufen. Und das wird auch die nächsten Jahre so bleiben, denn in der Fülle der Informationen müssen die Bücher gefunden werden. Sonst sind sie verloren. Und dabei spielen Metadaten eine entscheidende Rolle. Das gilt für gedruckte wie für digitale Angebote: Die Kunden sind online und je besser die Auffindbarkeit dort ist, desto eher wird gekauft, egal wo.
Dass Metadaten mehr sind als irgendwelche Felder für den Handel, die man mehr schlecht als recht ausfüllt, das ist in der Branche angekommen. In den USA natürlich schon etwas früher (für Einsteiger empfiehlt sich z.B. der Blogbeitrag von Michael Maher, für Wissenschaftsverlage z.B. die Folien von Cathy Giffi, für Publikumsverlage der schon betagtere Beitrag von Shatzkin). Neben den Treffen für data scientists und IT-Spezialisten aller Art werden sich im November auf dem Data Summit erstmalig auch im Rahmen der Buchbranche die Experten und Fachleute zu Metadaten treffen. Und das ist auch nötig, denn diese Disziplin muss raus aus den Hinterzimmern der Praktikanten, die mal eben noch den Onix-Standard vergolden sollen, um Geld zu sparen. “Discoverability” ist nicht umsonst und bedarf der Anstrengungen aller im Unternehmen, vom Lektor bis zum social media-Verantwortlichen, vom Vertriebsprofi bis zum Herstellungsleiter. Breinholst, selber Onlinehändler, nennt das Kind beim Namen, wenn er sagt, dass der Verlag seine Kunden kennen muss und die Metadaten das Bindeglied zwischen Produkt und Kunde sind. Die Händler können hier mit ihren Systemen unterstützen, aber die eigentliche Leistung muss vom Verlag kommen.
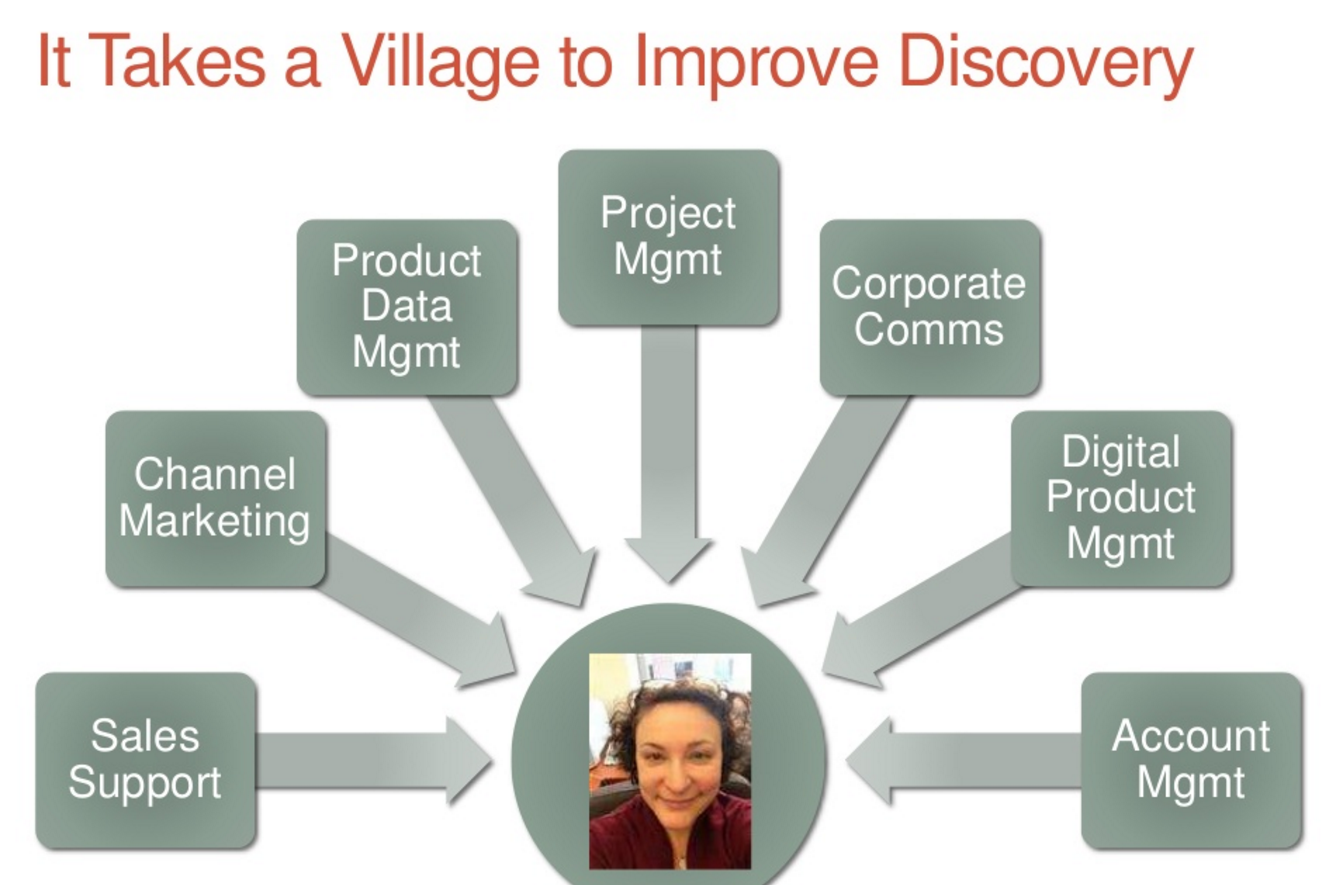
Catherine Giffi bringt es in Ihrer Präsentation auf den Punkt: It Takes a Village to Improve Discovery. Erst das gute Zusammenspiel der verschiedenen Abteilungen im Verlag ermöglicht eine erhöhte Sichtbarkeit der eigenen Angebote bei den relevanten Kunden (auf die Grafik klicken und dem link folgen).
Die Softwareanbieter wissen alle, dass die gute Pflege der Metadaten zur Grundausstattung gehören muss, von Klopotek bis pondus, von bookwire bis readbox, von knk bis newbooks-solutions. Hier wurde in den letzten Jahren Expertise aufgebaut. Das schwächste Glied in der Kette ist zur Zeit eher der Prozess in den Verlagen selbst und die richtige Nutzung der Daten.
Ein Text sagt meist mehr als 1000 Wörter. Denn der Leser nimmt immer mehr auf als das Geschriebene. Er wird den Text kategorisieren, einordnen, in seinem Gedächtnis ablegen. Und um diese Ablage geht es: Mit welchen Metadaten wird dieser Text gespeichert und wie lässt sich daraus erkennen, wonach ein anderer Kunde suchen mag.
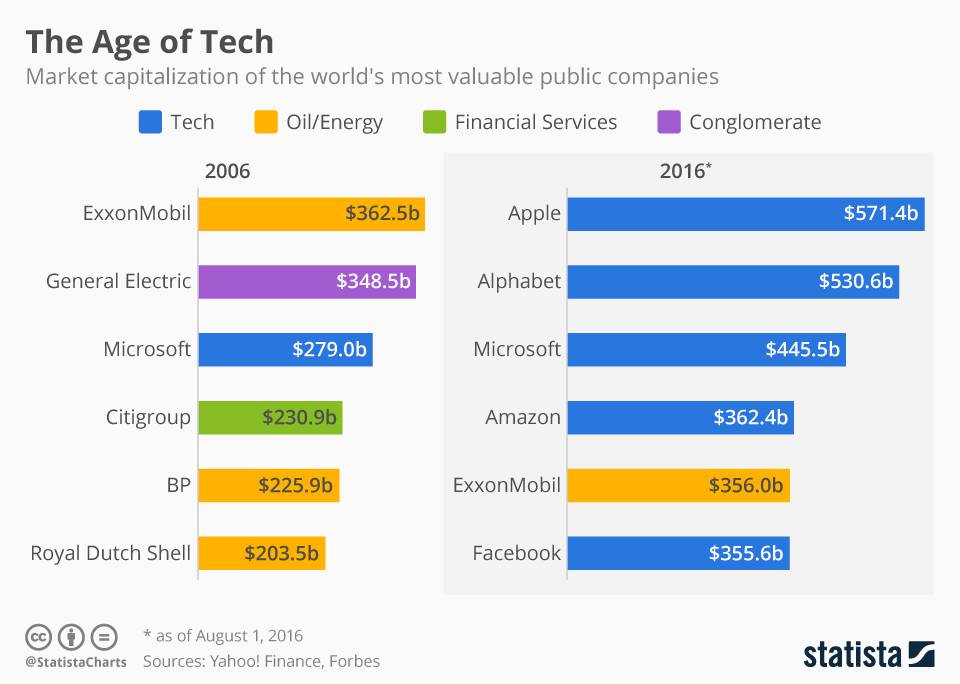
Daten sind das Öl des 21. Jahrhunderts. Das wissen wir mittlerweile alle, sind doch die relevanten Unternehmen genau die, die Daten sammeln, und nicht Öl fördern. Innerhalb kürzester Zeit spiegelt sich das auch auf den Aktienmärkten wieder.
Ein Blick auf Firmen wie Picturepark verdeutlicht jedem, dass Metadaten das Getriebe einer digitalen Ökonomie sind, und damit alle Firmen betreffen, die sich online ihren Kunden präsentieren. Metadaten sind so gesehen alle Daten die helfen, die eigenen Produkte besser darzustellen, damit die richtigen Kunden sie entdecken und dann kaufen. Dem folgend ist die richtige Metadatenpflege eine Aufgabe, die alle betrifft und sich dynamisch weiterentwickelt. Die Entwicklung eines DAM (digital asset management-systems) ist so wie die Entwicklung des CMS oder des CRM eine Daueraufgabe geworden (für Hartgesottene seien hier z.B. Blogbeiträge bei Picturepark empfohlen zu adaptiven Metadatenebenen oder Metadaten und Kontext).
Kein Start-up im Silicon Valley, keines der wichtigen Unternehmen weltweit wird nicht von sich behaupten wollen, dass sie aus dem Bauch heraus entscheiden. Jeder wird von sich behaupten wollen, “data-driven” zu sein, nah am Markt, am Kunden und vor allem flexibel. Nimmt man Experten wie Sri Raghavan beim Wort, so sind die meisten Firmen aber noch nicht so weit. Denn sie müssen drei Dinge übereinanderlegen: Infrastruktur, Menschen und ihr Know-how sowie Erfahrungen und Umsetzung.
Der Data Summit im November setzt hier an: Es geht um die nötige Infrastruktur und den Erfahrungsaustausch zu best practices und die nötigen Fähigkeiten der Mitarbeiter. Die Vorträge werden Beispiele zeigen, wie Daten zur Verbesserung der Angebote für die Kunden führen, wie das in der Vermarktung genutzt wird und wie Metadaten konkret bei Büchern Auswirkungen auf die Verkaufbarkeit haben. Die Erfahrungen bei der Umsetzung und Tipps hierzu sind ein zentrales Thema. Die round table-Gespräche bieten einen moderierten Einstieg in die Themen Onix 3.0, Marketing und Organisation und den Austausch mit den Experten aus den anderen Unternehmen. Natürlich gibt es schon gute und richtige Tipps zur Verbesserung der Datenqualität, aber die Musik liegt eigentlich in ihrer Nutzung bei der Vermarktung und der Produktentwicklung.

The Bestseller Code sorgt für Gesprächsstoff, ruft alle Verteidiger der Lektoren ebenso auf den Plan wie die Anhänger der Künstlichen Intelligenz. Dabei sollte man auf dem Boden bleiben: Viel zu komplex ist die nach wie vor die Vorhersage von Bestsellern. Denn in der Umsetzung lauern viele Details mit ihren Teufeln, die alle Bemühungen aushebeln können. Und doch sollten sich alle mit Daten auseinandersetzen, denn diese können einige Tätigkeiten erleichtern und sind für die digitale Vermarktung zentral.
Von Produktverkäufen über Kundendaten bis zu Metadaten kann man ja so ziemlich viel sammeln in der digitalen Welt. Und manche meinen auch, damit Bestseller schon identifizieren oder sogar vorhersagen zu können (zur aktuellen Diskussion rund um das Buch “The Bestseller Code” hier der empfehlenswerte Beitrag von Andrew Rhomberg). Niemand weiß, wie künstliche Intelligenz in zehn Jahren unser Leben bestimmen wird und es sind der Daten viele, die gesammelt werden können. Wer vor lauter Wald die Bäume nicht mehr sieht, dem sei empfohlen, sich auf den Baum “Metadaten” zu konzentrieren. Der bietet nämlich schon einmal einen sinnvollen Einstieg und verspricht schnelle Gewinne.
Metadaten sind mehr, wie wir in mehreren Artikeln schon beleuchtet haben (hier z.B. eine Zusammenfassung der diesjährigen Konferenz zu smart data, zum Prozess der Metadatenoptimierung in Verlagen von Tobias Streitferdt, zu Metadaten und Vorschauen, zur Macht schreibender Computer und kognitiver Systeme oder zur Metadatenvergabe bei Amazon).
Wir hoffen auf ein Treffen auf dem Data Summit und anregende Gespräche mit Ihnen. Wenn sich die Dinge so schnell ändern um einen herum, dann ist der fachliche Austausch umso wichtiger.