

Google wurde vor Jahren dafür gefeiert, Grippewellen gut vorhersehen zu können, weil das Suchverhalten vieler früher als der Besuch beim Arzt darauf hinweist, dass Bedarf besteht. Aber sie waren beim Start eben nur besser als die der Gesundheitsbehörden. Und der Dienst wurde 2015 eingestellt nach einigen Schnitzern. Und auch die Uni Osnabrück konnte auf der Basis von IBM Watson 2019 keine relevanten Ergebnisse für die Corona-Pandemie liefern. Warum?
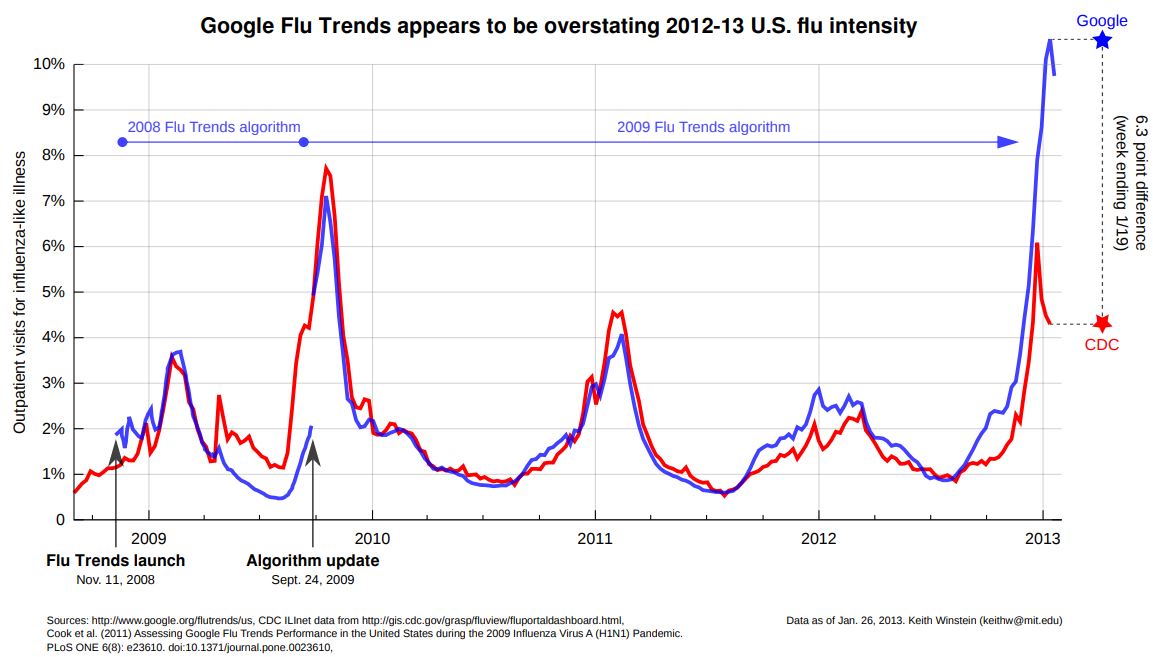
Google Flu Trends startete 2008 und wurde in der Wissenschaft als neue Errungenschaft hochgelobt, ähnlich wie die Titanic bei ihrem Stapellauf als unsinkbares Schiff. Aus dem menschlichen Suchverhalten nach den üblichen Begriffen rund um Grippe wie Husten, Schnupfen, Erkältung, Fieber etc. versuchte man früh zu erkennen, wie sich die jährliche Grippewelle entwickeln wird. Nach anfänglichen Erfolgen (man sieht dies gut an den sich überlappenden Graphen – blau ist Google, rot sind die Daten der CDC, der nationalen Gesundheitsbehörde in den USA), wurde der Dienst 2015 eingestellt. An dem hier dargestellten Graphen und der Analyse von Carey Goldberg von 2013 erkennt man, dass die Vorhersagen von Google deutlich zu hoch lagen. Das Problem: Das menschliche Suchverhalten ist zu komplex, um daraus einfache Prognosen ableiten zu können (siehe hier eine Zusammenfassung der Einschätzungen von Spezialisten in der SZ vom März 2014). Und zugleich muss man erkennen, dass das Geschäftsmodell von Google eben nicht im Kern die Vorhersage von Grippewellen beinhaltet: Dies zeigt sich an der Kritik an Google von Lazer und Kennedy: Ein Grund für die Fehler lagen auch in der laufenden Veränderung von Googles Suchalgorithmus. Dieser hat zum Ziel, Kunden zu den für sie passenden Seiten zu leiten – und dafür durch gezielte Werbung Geld einzunehmen. Das lässt sich eben nicht vergleichen mit den Zielen einer Gesundheitsbehörde! Zugleich wäre es verfrüht, diese Technologie sofort abzuschreiben, wie die Gesundheitsexpertin Lorraine McDonagh 2018 auf dem offiziellen Blog der UCL am Beispiel von Google Trends zeigt: Man muss die verschiedensten Faktoren in Relation setzen, die zu unterschiedlichstem Suchverhalten führen können.
Wo bleibt Google Corona Trends? Und warum bieten Google und Co. keine sinnstiftenden Antworten?
Die letzten Monate vergeht kaum ein Tag, an dem nicht über neue Dienste und Errungenschaften im Bereich der “Künstlichen Intelligenz” berichtet wird. Dabei spiegeln sich Ängste vor einer Übernahme der Menschheit durch Computer wie Sehnsüchte nach einer besseren Welt gleichermaßen in den möglichen Zukunftsszenarien. Wir haben an dieser Stelle mehrfach auf Googles Potenzial hingewiesen, das sich z.B. bei Google Maps zeigt, einem der mächtigsten Werkzeuge zum Erfassen und Steuern von menschlichem Verhalten neben Suchmaschinen. Aber das darf nicht darüber hinwegtäuschen, dass wir es im Bereich der KI mit Denkprozessen zu tun haben, die bei weitem noch nicht die Fähigkeit von Würmern erreicht haben (siehe hierzu auch unseren Verweis auf die Einschätzung zum Potenzial von Algorithmen durch die Expertin Hannah Fry).
Am 3.4. hat Google erstmals sichtbar eine für seine Verhältnisse fast schon ärmlich anmutende Seite zusammengestellt, ein Doodle ins Leben gerufen mit brav zusammengestellten Informationen, einem knowledge graph, wie man ihn schon längst kennt, gespickt mit den offiziellen Seiten der Regierung.
Wo bleibt hier die künstliche Intelligenz, möchte man fragen.
Die Antwort ist simpel: Durch einen reinen Blick auf die Vergangenheit und bisherige Verhaltensweisen erhält man viele Daten und daraus kann man Muster ableiten, aber noch lange keine sinnvollen Antworten. Dazu muss man erst die richtige Frage stellen an die Daten und dann die Auswertung bewerten. Und das ist auch eine Frage des Geschäftsmodells: Wenn Daten zu bestimmten Zielen gesammelt werden, sind sie noch lange nicht für andere Zwecke gut nutzbar. Und Marketing (das ist das Thema von Google und Facebook) verfolgt andere Interessen als sie ein Staat verfolgen müsste, wie z.B. den Schutz der Bürger, Meinungsfreiheit, demokratische Aufklärung etc.
Wie Kasparov den Schachcomputer muss man die “künstliche Intelligenz” zu führen wissen. Sie kann uns nämlich moralische Fragen nicht abnehmen, die Abwägung zwischen wirtschaftlichen, nationalen, gesundheitlichen und vielen weiteren Interessen. So kann uns vielleicht eine App helfen, Infizierte schneller zu erfassen, werden Algorithmen durch Mustererkennung die Produktion von Impfstoffen erleichtern und ähnlich gelagerte Probleme lösen helfen – wenn wir die Aufgaben klar vorgeben. Mögliche Aufgabengebiete für machine-learning liegen auf der Hand (siehe hier eine Übersicht), aber sie müssen geplant, gesteuert und organisiert werden. Dieser Hinweis auf eine besondere Suchmaschine für Wissenschaftler zur Erforschung des Virus vom 4.5.2020 ist dabei eine Initiative unter vielen.
Und hieran wollen Google und Apple zusammen arbeiten, so wie auch Mobilitätstrends veröffentlicht werden, um daraus Schlussfolgerungen ziehen zu können. Die Google News Initiative versucht mittlerweile über das Tool Coronavirus Search Trends, die verschiedenen Suchstrategien der Nutzer Journalisten zur Verfügung zu stellen. Auch der “Fact Check” von Google versucht hier gegen “Verschwörungstheorien” und fake news bei Corona Abhilfe zu schaffen, wenn man z.B. “Corona” oder bestimmte Personen eingibt.
Macht eine App Sinn?
Die Diskussion um die App zur Nachverfolgung von Infizierten zeigt aber, dass auch eine technologische Lösung noch keine Lösung des Problems darstellt. Die Übersicht zu den Herausforderungen bei der Entwicklung der App auf zeit.de vermittelt schon auf einen Blick die Komplexität der Aufgabe. Die kritische Analyse von VentureBeat zeigt auf, warum allein die Umsetzung viel zu viele Hürden hat, um an sinnvoll verwertbare Daten zu kommen. Die Empfehlung mündet in der Antwort: Die App bringt uns jetzt nicht weiter, aber für die Zukunft bei einer weiteren Pandemie. Das folgt ganz dem Ansatz von minimal viable products, die zum Test gelauncht werden, um durch die Kundenrückmeldung dann Verbesserungen zu erzielen. Nur haben wir es hier mit Menschenleben zu tun und der Frage, worauf man Ressourcen verwendet und ob man sie nicht sinnvoller einsetzen kann. Und man kann auch ein mvp sinnvoller entwickeln, wenn man nicht von vorne herein daran glaubt. Deshalb verweisen wir hier auf die wie immer lesenswerte Darstellung von Luciano Floridi. Eine App macht wenig Sinn, weil sie bei zwei Prüfungen durchfällt.
Eine “validation” (= macht diese Art der Lösung Sinn) überprüft, ob die App rechtmäßig, nötig, proportional angemessen, zielorientiert und für den einen Zweck ausgerichtet ist. Selbst wenn man das alles unterstellt, zeigen sich leider Schwierigkeiten bei der “verification” (= macht diese Form der Umsetzung Sinn). Einfacher gesagt, ein Blick auf die usability zeigt, dass man auch im besten Fall nicht genügend Personen dazu bringen kann, diese App zu nutzen, um aussagekräftige Daten zu erhalten. Die App ist höchstwahrscheinlich nicht effektiv. Das hat etwas mit der Durchdringung zu tun, aber auch der “digital literacy” ihrer Benutzer. Die Möglichkeit der Umgehung von richtigen Messungen und Betrug sind neben den Fragen zur Privatsphäre zu offensichtliche Schwierigkeiten. (Hier setzt auch die Kritik vieler Wissenschaftler an, die jetzt ausgestiegen sind.) Die Daten werden zu keinen tragfähigen Ergebnissen führen können.
An dieser Stelle raten wir, die jetzige Kritik aufzunehmen und die Energie in eine Weiterentwicklung des ersten Lösungsversuchs zu stecken. Jedes Start-up weiß was pivoting bedeutet und die Änderung des eigenen Geschäftsmodells. Man darf sich nicht zu schnell auf eine vermeintliche “Wunderwaffe” verlassen. Sonst täuscht man politischen Aktionismus vor, der dann von den nachfolgenden Regierungen kuriert werden muss.
Daten müssen erst einmal richtig aufbereitet und zugeordnet werden, denn meistens wurden sie für einen anderen Zweck erstellt. Ein Hintergrundbericht von Zapp zeigt, wie die Johns Hopkins-Universität lange ungefragt die Daten der Berliner Morgenpost bei der Erstellung der eigenen Statistiken verwendet hat. Daten sind nie objektiv, sondern geben immer nur einen Standpunkt wieder. Und sie sind immer fehleranfällig. Wäre dem nicht so und alles wäre schon klar, könnten sich nicht so viele neue Firmen anbieten, die vorhandenen Datentöpfe zum Coronavirus neu ordnen zu wollen und sich als KI-Dienstleister gegen die Corona-Krise positionieren.

Dieses Dashboard der Deep Knowledge Group versucht sich an einem Ranking in Bezug auf die Sicherheit von Ländern während der Corona-Krise. Mit Hilfe von über 70 Parametern werden Daten aus über 130 Ländern regelmäßig abgerufen, aktualisiert und in Beziehung gebracht. Daraus entsteht sich wie bei einer Balanced Scorecard eine Übersicht, die Vergleiche zulässt. Entscheidend ist hier, dass die Datenquellen regelmäßig überprüft und offengelegt werden, dass die Parameter von Experten erstellt, überwacht und verändert werden und dass die Abhängigkeit der Bereiche voneinander sichtbar wird. Offensichtlich ist, dass die Erstellung derartiger Übersichten ähnlich dem PISA-Test oder Olympischen Spielen immer nur eine Momentaufnahme darstellen – aber allemal besser sind als nichts. Der Olympiasieger muss nicht der beste Athlet sein, aber im Moment des Wettkampfes war er das. Deutlich wird hier, dass die Regeln für den Wettkampf nicht von der Stoppuhr gemacht wurden, sondern von Experten. Soviel zur Bedeutung von KI. (Nähere Angaben siehe unter http://analytics.dkv.global/data/ranking-framework-and-methodology.pdf)
In einer Serie von Artikeln versuchen wir uns dem Thema Medienkompetenz zu nähern. Die Corona-Krise schärft unseren Blick. Und sie weist uns darauf hin, was wir in den nächsten Jahren im Blick behalten sollten. Dabei gilt natürlich ein Spruch aus dem Big Data-Management: “What´s right on Monday is wrong on Tuesday”. Jeden Tag verändert sich die Datenlage und führt zu neuen Analysen. Trotzdem müssen wir auch längerfristig planen und dabei agil Annahmen immer wieder überprüfen. Mit unserem neuen Studiengang Digital Media Manager wollen dazu beitragen. Der gemeinsame Diskurs muss aber auf vielen Ebenen geführt werden. Wir freuen uns deshalb über Rückmeldungen, Anregungen und ein Weiterdenken.
Die Themen im Überblick
- Warum alle Zahlen falsch und richtig sind
- Warum uns KI nicht vorgewarnt hat – oder wo war Google Flu Trends?
- Warum Handeln in der Krise Trumpf ist – aber nachdenkliches Agieren in komplexen Systemen lebensnotwendig
- Wie man das eigene Narrativ kritisch bewerten kann
- Was Medienkompetenz in der Corona-Krise bedeutet